

在一个大小核系统中,大核是相对于小核而大的,小核是相对于大核而小的,你不能跨越系统去说这个小核就一定小,大核就一定大。就像在Apple的A系列那里,ARM的公版Cortex A77/78之类核心能叫“大核心”吗?Alder Lake的Gracemont相对于Golden Cove是小没错,但是相对于今天的“大核心”Skylake、Zen2来说并不算小核心。
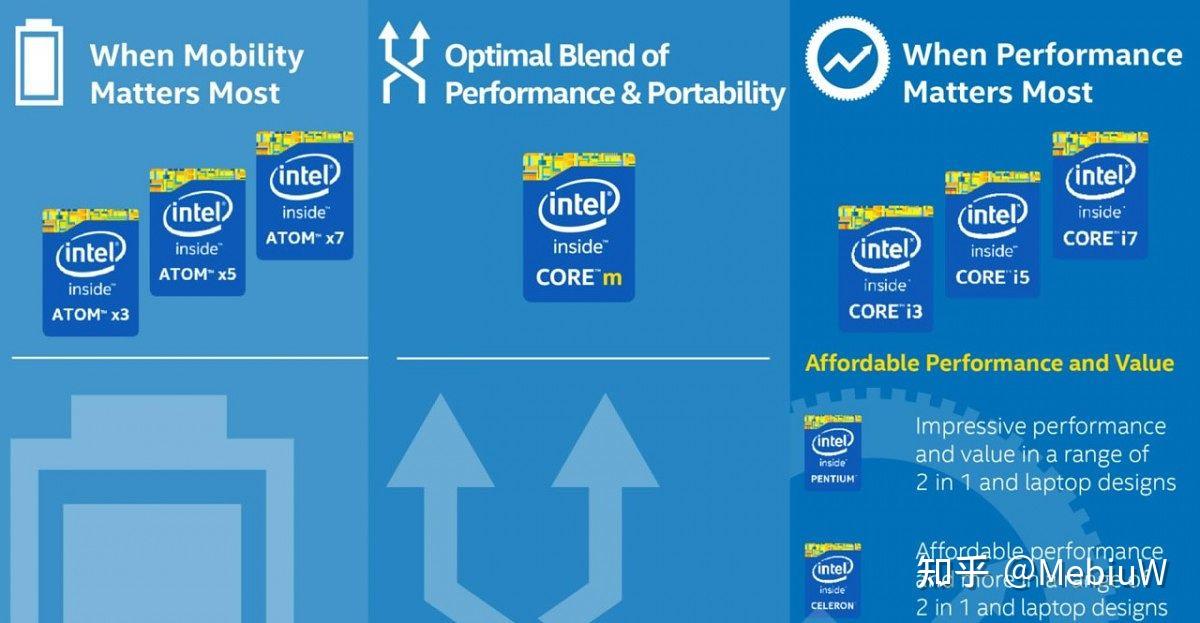
Intel的小核心起源可以追溯到Intel的Atom产品线,Intel曾觊觎在移动市场分一杯羹,而自己主流的酷睿产品线因为高成本和高功耗的问题不能进入到这个市场,所以Intel就单独开了一条产品线。曾经红极一时的Intel寨板就是用的这个产品线。只不过最后因为种种原因,Intel没在这条产品线上讨到什么甜头。
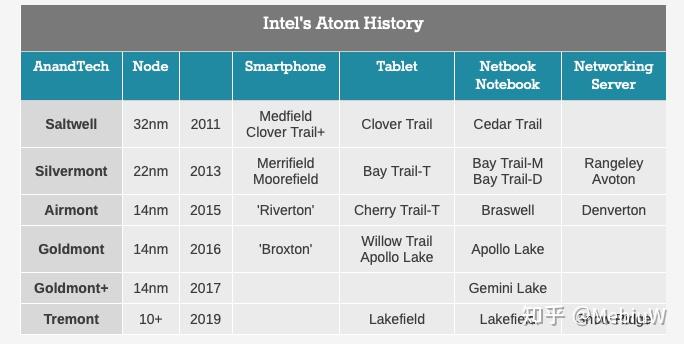
Atom在消费级的失败,虽然导致了Atom品牌在消费级直接暴毙,但是Atom却一直没有死,而且一直活的好好的。首先Atom这个品牌全面转向了“低端”企业市场,主攻物联网基站、网络服务等追求低能耗和高可靠性的产品线,有效的防守“ARM”的进攻。其次,Atom的小核心换了一个名头,以赛扬和奔腾的品牌(譬如N系列,J系列)也依旧在低端消费级活跃着。 因此,Atom这条线其实也一直在默默的更新着。现如今,Atom的最新产品线已经进化到了Tremont,而下一代就是Alder Lake的Gracemont了。
Intel这两年最大的困境是,没有新工艺来制造Core Xeon新产品,造成了挤牙膏的错觉,但是对于本来就没用最新工艺的Atom产品线来说,就基本没遇到这个问题。 Atom这两年一直在稳定有序的提升着核心设计,基本每次核心大改都做到了20%-30%的IPC提升。最新的Tremont核心对比上一代Goldmont Plus提升了30%的IPC,并且用上了Intel的10nm。

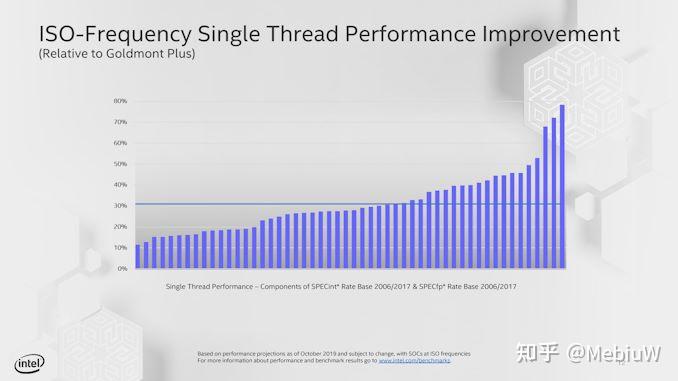
所以相比于Intel大核心Core/Xeon万年用13年设计完成的Skylake来说,Atom一直在进步着。 2013年的Atom设计相对于Skylake的的确确是小核心设计,但是2019年的呢?2021年的呢? 虽然Atom相关产品线的测试不好找,但我们还是希望靠数据来说话,一起来看看Atom现如今到底什么水平了?
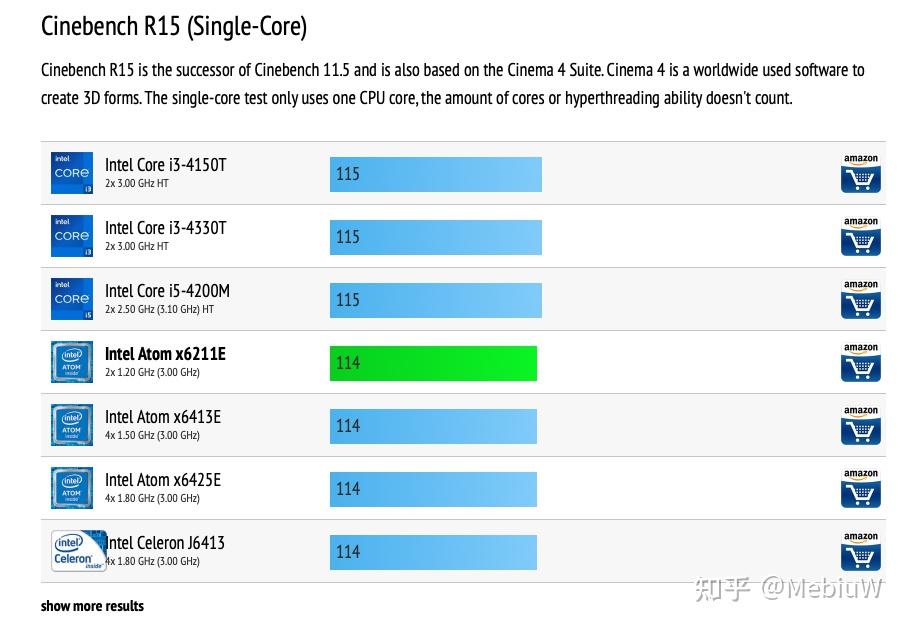
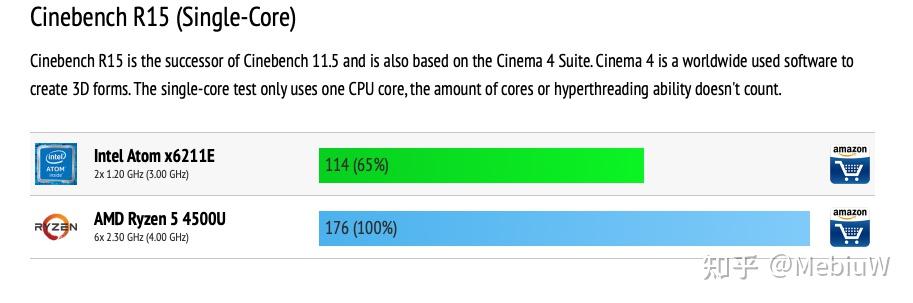
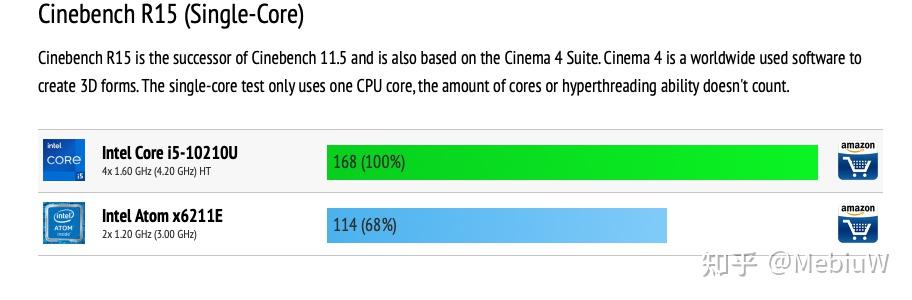
首先是我非常不喜欢的R15成绩(因为成绩实在不多,只能尽量展示了), Atom X6211E有两个Tremont核心,单核睿频3.0G,R15单核得分114分,算起每Ghz性能基本和Haswell架构持平。大体上是4G Zen2核心的65%的成绩,4.2G Skylake的68%,折算R15下表现 是Zen2的86.7%,Skylake的95%。
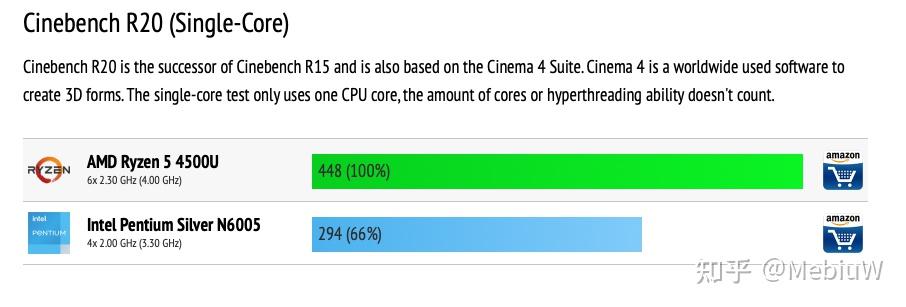
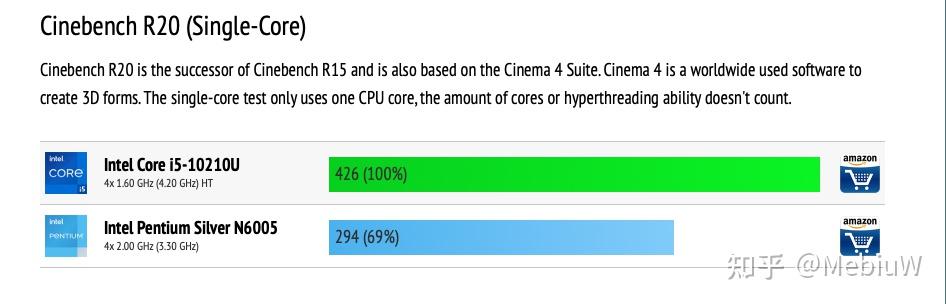
另一个Tremont产品,Pentium Gold N6005,有四个Tremont核心,单核睿频3.3G,R20下的表现是4G Zen2的66%,4.2G Skylake的69%, 消除频率差异后折合80%的Zen2 ,87.8%的Skylake表现。
在更加综合的Geekbench 5的跑分里,Tremont的IPC表现更比R15 R20好,在我的数据库记录里,其已经非常接近Skylake和Zen2的表现了,基本上是表现比较一般的Skylake和Zen2的90%的IPC,对比最好的Zen2则也有80%的程度。
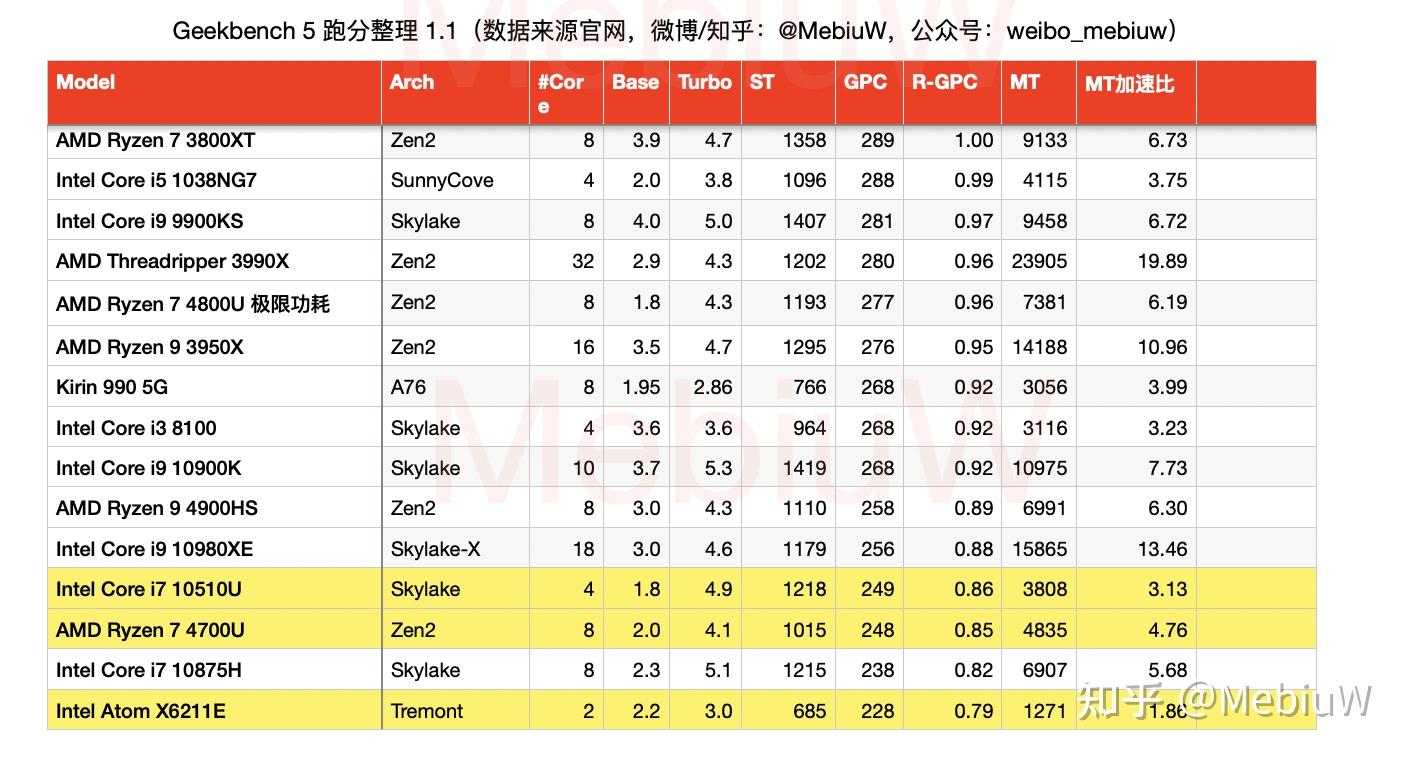
所以总体看下来,现阶段的小核心Tremont都已经到了Skylake的85%附近的水平了,而下一代Gracemont按照其正常的提升幅度,在很多通用跑分中IPC超过Skylake是很Make sense的,在大部分场合中说Gracemont和Skylake/Zen是一个级别的核心不算太过分。这个X86“小核心”对比当今主流的X86“大核心”,真的不是A55对A78那种关系。Gracemont这个级别的小核心,搭配3.0G+以上的频率,拿来做多核负载真不是凑数多核。
如果打个比方的话,Alder Lake 的全线产品,近似于多核负载时,附赠了一个AMD Zen 2的4700U(8C8T没有超线程),真的很鸡肋吗?
说Gracemont之前可以先聊聊它的前辈Tremont,Gracemont是Tremont改进过来的,
按照intel的说法,Tremont对比上一代Goldmont Plus的IPC提升达到32%,起点低就是任性,可以看一下架构图:
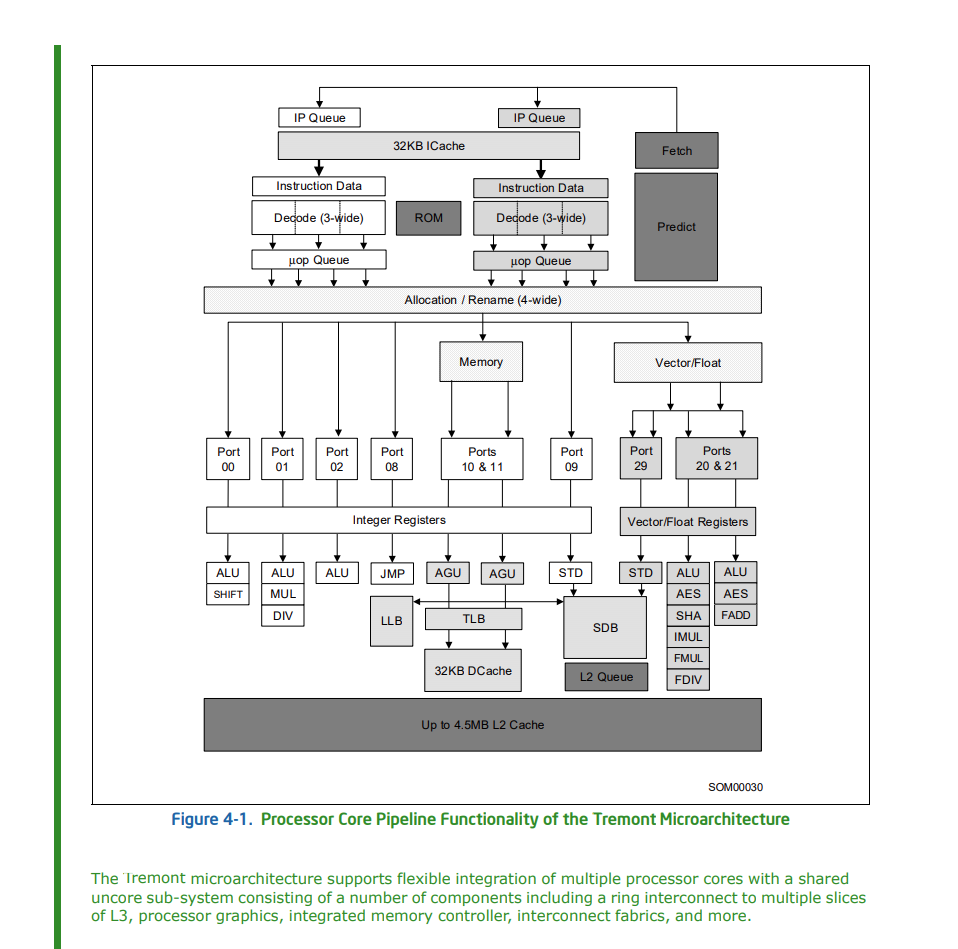
双前端六解码,这应该是X86这边第一个6解码的微架构,居然出现在小核上,
208ROB,这个略低于SKL/ZEN2/Cortex X1的224,高于Haswell/ZEN的192,
L/S不清楚,
后端十个端口,整数浮点分离设计,这就和intel一贯的风格不符了,
因为intel的Willow Cove / Sunny Cove / Skylake / Haswell / Sandy Bridge全部都是整数浮点融合型设计
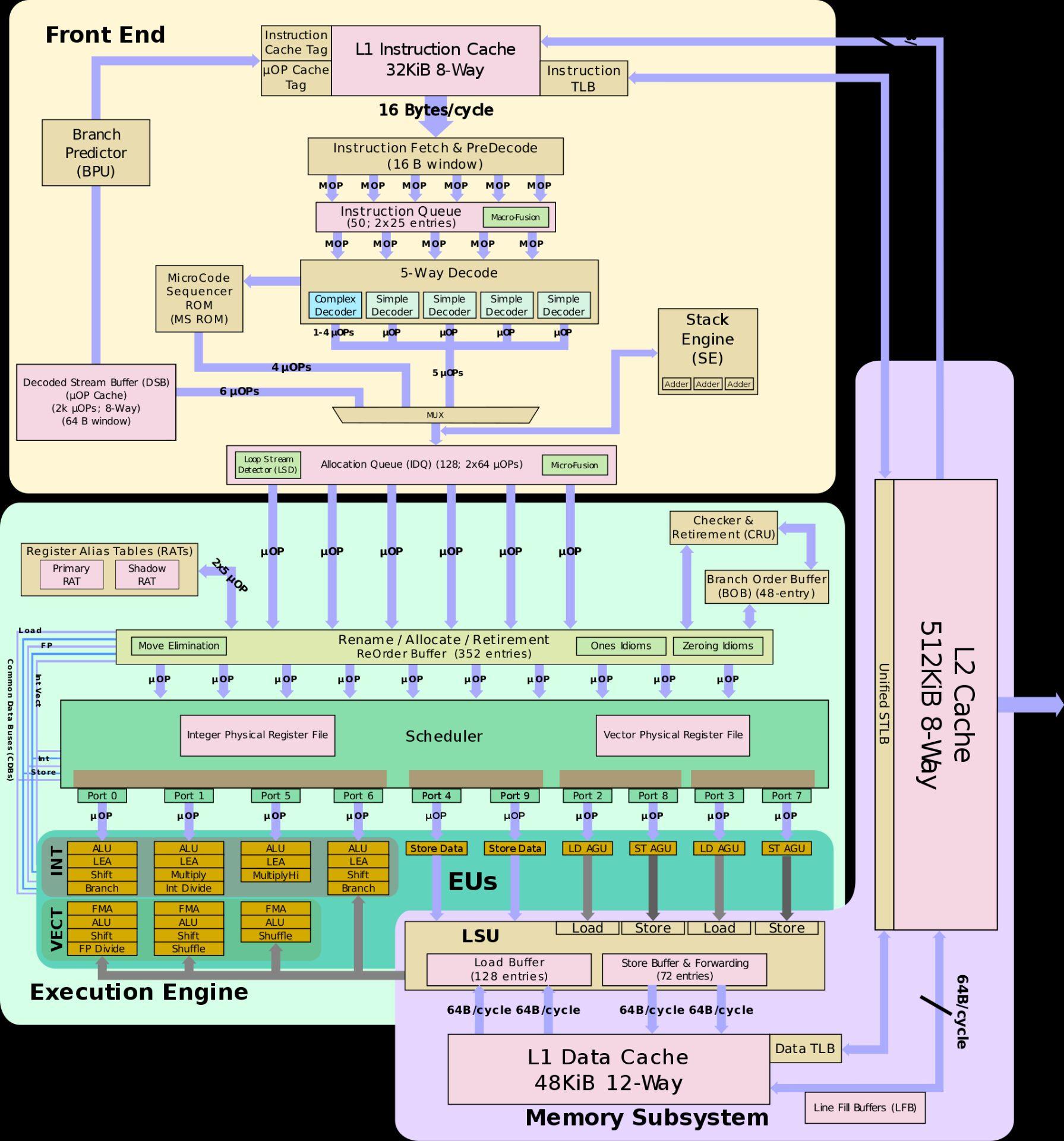
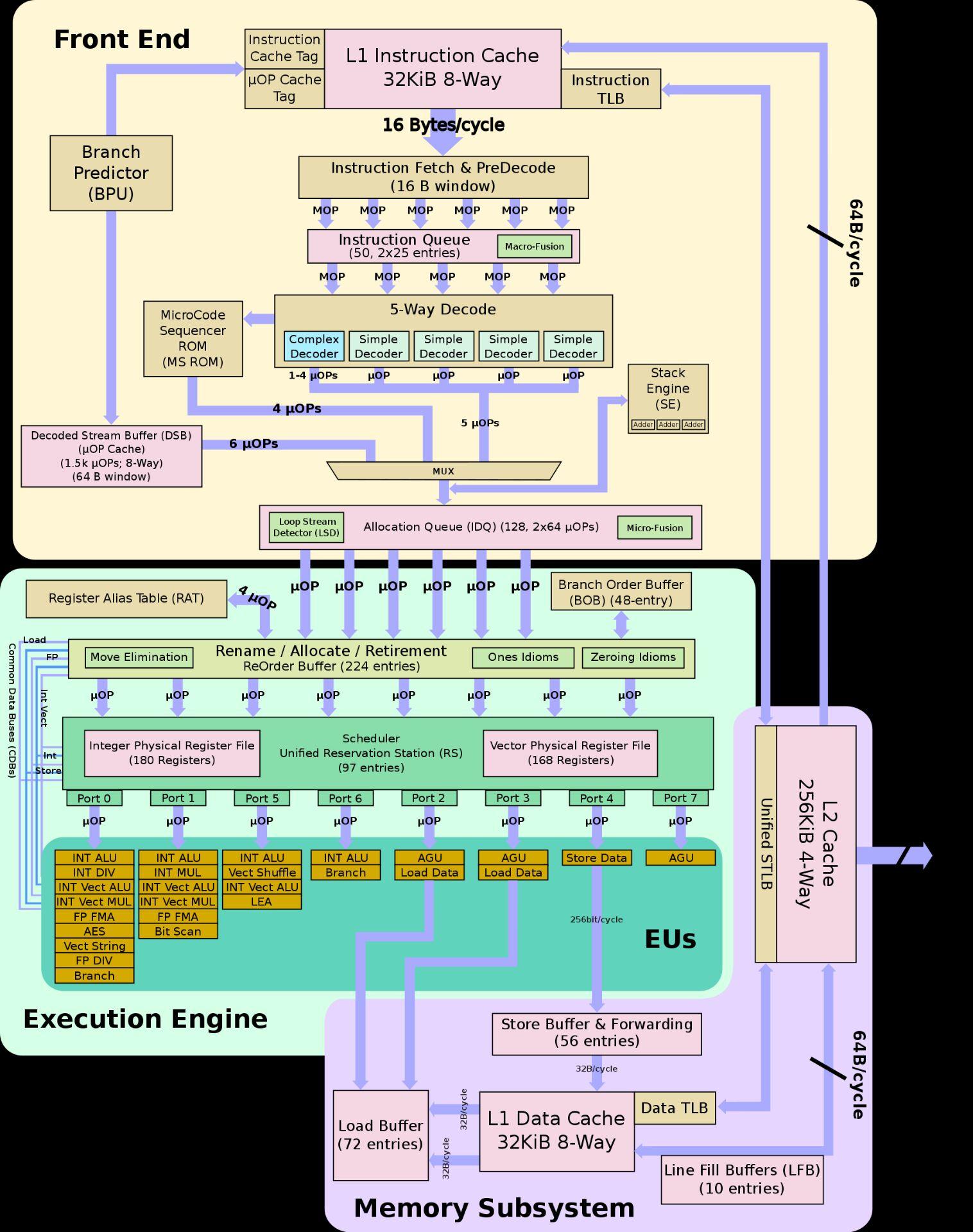
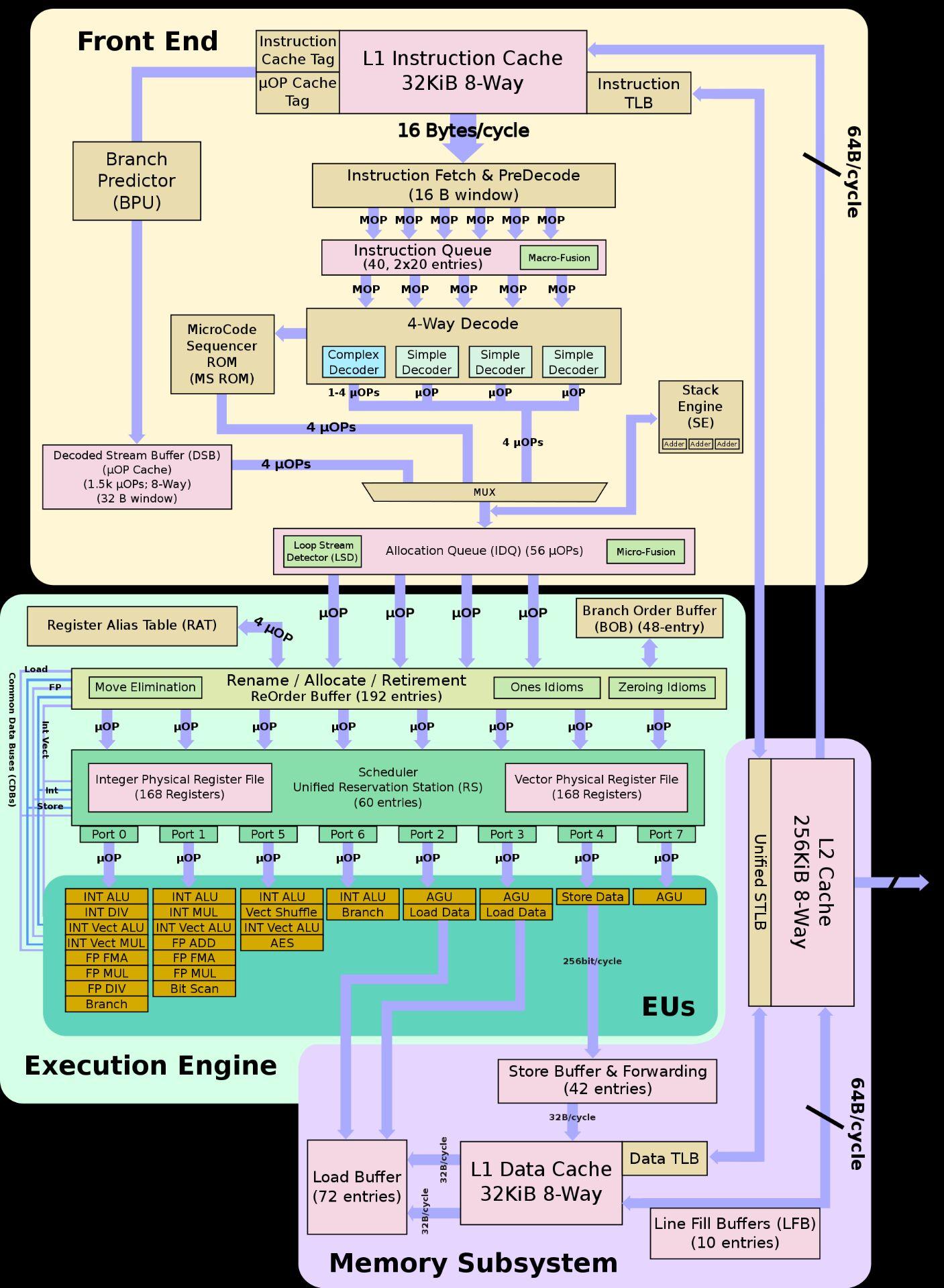
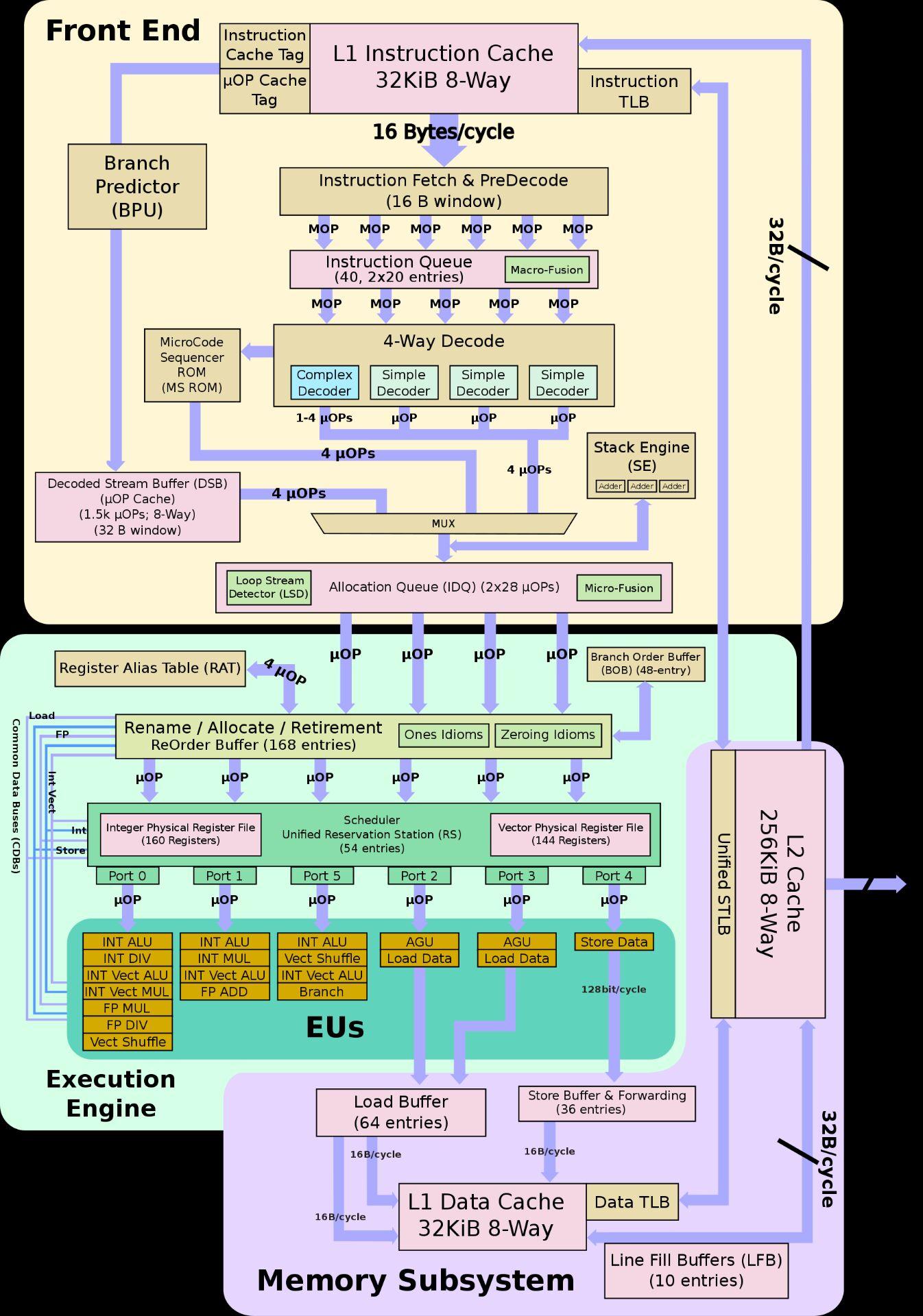
所以intel这个Tremont后端设计和它的老前辈比起来就不是一种设计思路,
反而更像AMD的ZEN2 / ZEN3以及苹果的Firestorm
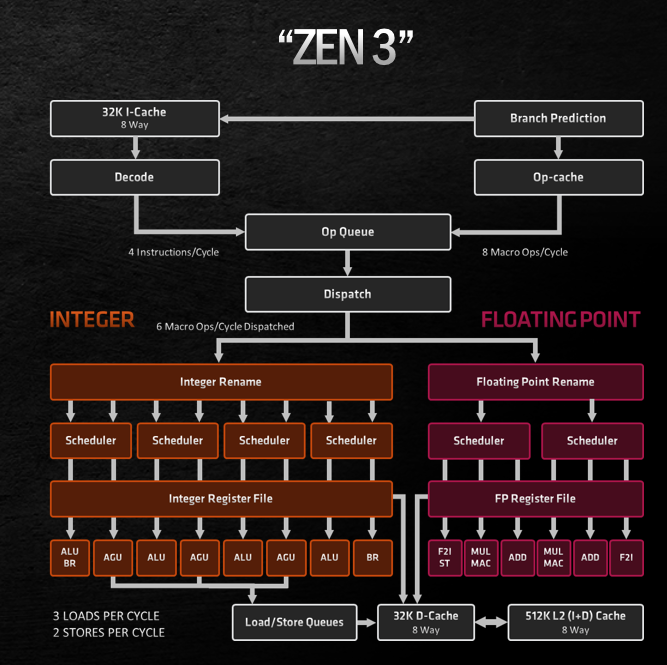
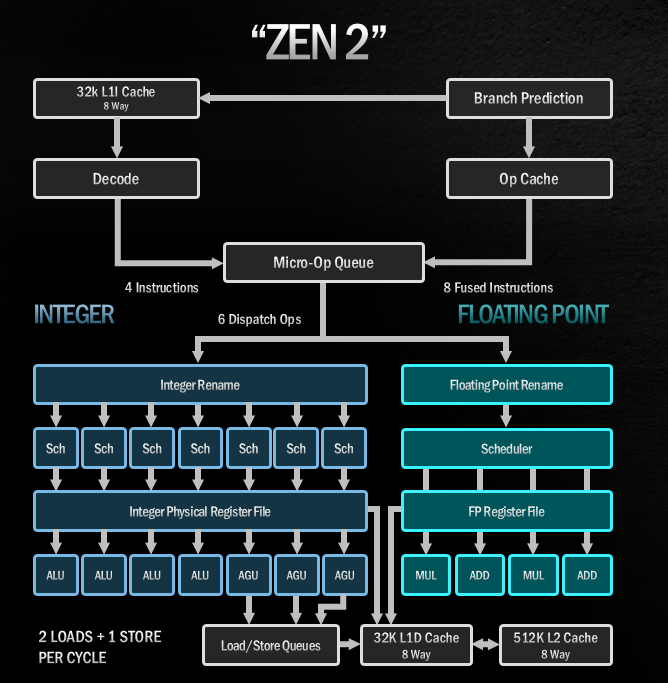
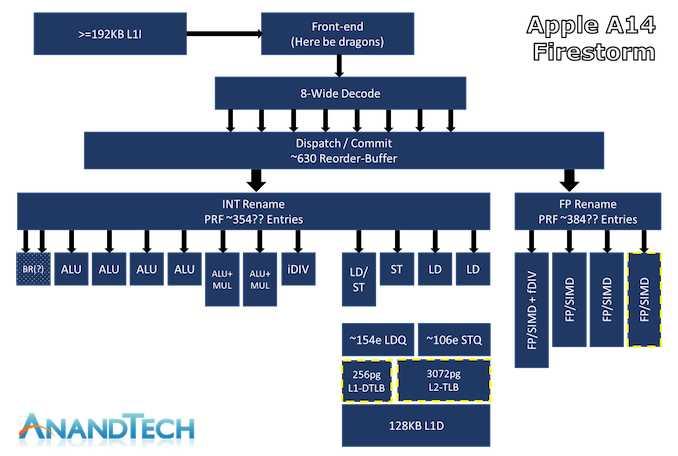
所以这个小核和intel传统的大核比起来,似乎有另一手准备,
从IPC上来看,这个小核也还好
但是在部分项目里面却能够获得可观的成绩,从很多成绩中已经证明了这个小核其实跑分挺厉害的,特别是跑渲染类,在不带AVX的渲染里面,同频下Tremont几乎和Haswell差不多了,带AVX的渲染里面和IVB表现差不多,
Gracemont不出意外将会继续沿用Tremont那套架构,在Tremont的架构上进行增量更新,将支持AVX/AVX2,Tremont是不支持AVX的,纯SSE跑分里面Tremont已经达到了Haswell的水平,加了AVX之后它的性能以及适用性应该更广才对,所以这个小核真的“小”吗?
后续加强一波跑分追Skylake真不是奢望,
由于Gracemont还未公开,但是传统艺能是可以猜,我觉得前端可以不用改了,双前端六解码挺好的,ROB可能会增加到256左右,然后后端的int和FP部分会继续增加执行单元,也许会增加到14个左右的端口,整数部分ALU增加1个,AGU增加1个,L/S进一步增强,浮点部分再加两个端口,
增加AVX/AVX2的支持,不过究竟是以4X256来实现还是2X256FMA来实现又或者说是2X256那样来实现就不好说了,等intel揭晓,
为什么前面总在说跑分?
说来话长,
我们都知道intel有Ring总线,LCC Ring总线堆核是有上限的
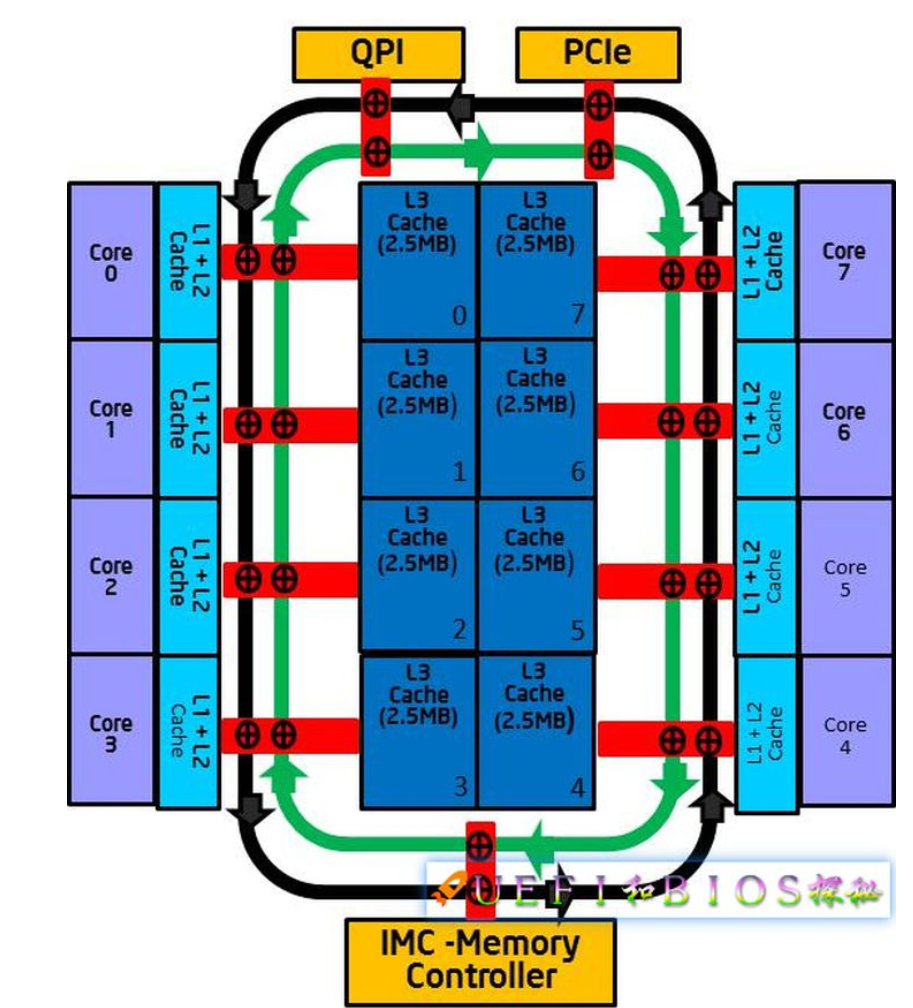
而超过LCC Ring的堆核上限之后,目前只能选择使用Mesh架构,也就是intel的至尊平台/服务器平台那套班子,以前还有MCC Ring,也就是类似于1.5 Ring的结构
LCC Ring BUS有着优于MESH总线和IF总线的延迟,intel暂时还不愿意放弃这套总线,
另一边AMD用IF总线在普通消费级实现了16C32T,多线程性能对比intel的普通消费级i9遥遥领先,基本上追不上,10C20T对于普通人来说确实非常好且非常过剩,但是架不住隔壁16C32T跑分的轰炸啊,在很多主流跑分软件里面,多线程性能AMD还真就压着intel打的,
所以intel换了一种思路,决定用少量的大核来替换多个小核来实现更高的多线程跑分,原本大核的缓存由小核们共享,i9的小核可以分到0.3MB/C的L2和0.75MB/C的L3,这个L2倒是不小了,比Skylake的还大,L3就很小,非常适合跑分
不说打赢AMD的16C,也至少要求要追回来很多,
所以intel在Alder Lake这里选择用两个大核换取八个小核这种思路,
intel这个小核还和ARM/LKF的小核是一种思路吗?
后者的小核明显更偏向能耗,次要追求性能,
而ADL的小核,则是完完全全被intel拿来疯狂刷分的,所以ADL的小核是更偏向于性能,能耗的话因为小核本身就小,所以能耗相对于大核Golden Cove来说要高很多,也算是次要追求能耗了,
换句话说,如果真像很多人想的那样,Gracemont最后做出来频率2GHz左右,那八个小核的跑分性能还不如两个大核或者只比两个大核高一点,那intel又是何必搞这一遭?
intel是想通过换区这八个小核获得远胜于两个大核的性能,
然后是很多人喜闻乐见的调度问题,这就交给intel/巨硬去解决吧,
成也小核败也小核。
大核其实有三个问题,以现役最强大核Willow Cove来说:
1.耗电。TGL-U的频率功耗比(主要指低频)打不过zen2,就靠微架构优势撑一撑。
2.面积。单个WLC面积差不多有10mm^2[1],Cezanne的zen3单个核只有5.5mm^2[2],虽然前者的缓存更大(1.25M+3M vs 0.5M+2M),但面积上的确存在很大劣势,增加了堆核成本。(一部分要怪怪制程工艺)
3.堆核。ringbus的最佳上限是10核左右,而mesh的话核心不多又开销太大。如果换回双ring(以前Bradwell-EP用的)的话有NUMA问题(虽然AMD一直有),而且单独维护一套受众小成本划不来。
再来看看小核怎么填补这些问题的:
1.耗电。atom常年专注省电设计,最初甚至是P5延伸过来的顺序执行,到现在都不愿意上高功耗的SIMD。intel自己给出的ppt里能耗比比大核强。
2.面积。也很省面积,4个GRT还不到1.5个GLC大(参考LKF上4个TNT差不多1.2个SNC大[3]),毕竟没有uop cache等设计,也没有巨宽的SIMD。
3.堆核。4核为一簇挂在ringbus上,这很zen2(考虑到整数/向量流水线分离就更加像了),堆核潜力直接x4。
所以说大小核设计能够互补,的确是intel眼中很有前途的做法。
一些人批评intel“不愿意堆核”、“整天推没用的AVX512”、“盲目追求高频”,这样看来可能小核可能才是他们想要的……
小核的性能其实并没有那么弱,大家不能拿着silvermont寨板的眼光去看待。(虽然论浮点向量性能差距还是很明显)。
而且gracemont本身相对于tremont也是有提升的。
支持AVX2算最明显的一点,不过别指望向量能力有多疯狂的提升,参考一下zen1是怎么用128bitALU去支持AVX2的。
前端后端加宽还在继续。前端的双解码簇是很有意思的设计,我在写一篇相关的文章,但是拖延症犯了。而后端规模在tremont就不算小了(毕竟只要考虑128bit的数据宽度)。
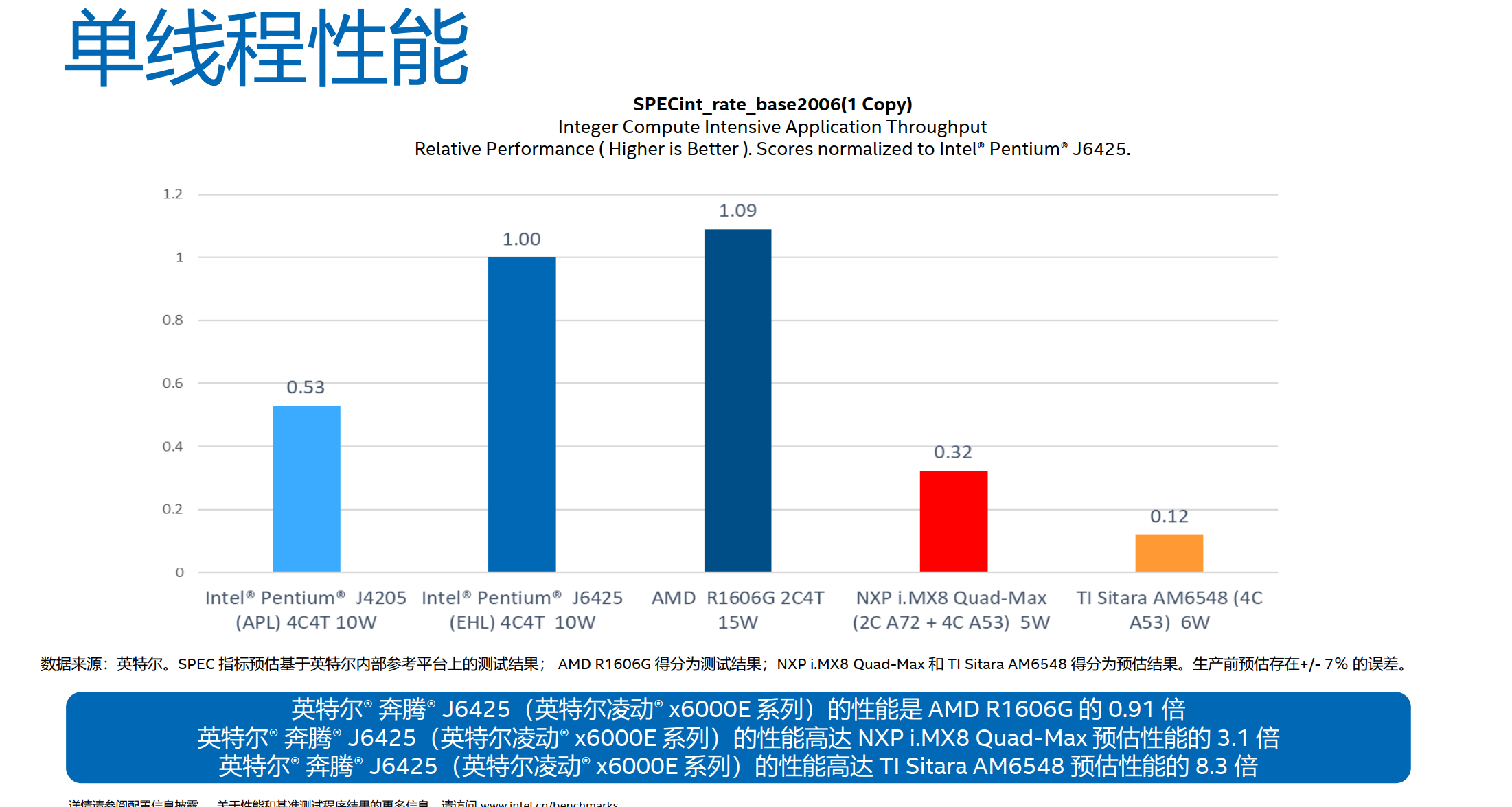
@超合金彩虹糖 的回答里放了一张PPT,透露了一个讯息,本世代的Tremont微架构,J6425,已经能做到IPC上超过了AMD的Ryzen 1606G,单核性能则接近Ryzen R1606G,这是一颗基于Zen架构的频率3.5GHz的嵌入式处理器。当然排除掉APU阉割L3的传统艺能,下一代Gracemont单核达到目前Zen2移动处理器的单核性能也并非是遥不可及。
有人提到了它相对于NXP的一颗处理器的跑分,1.6G的A72,这里放一个可能规格比较接近的处理器,通过Config.txt将频率调整到1.6GHz的树莓派4B,操作系统是Raspbian,编译器是gcc8.3
编译选项:-mabi=accps-linux -fgnu89-inline -fno-strict-aliasing -Ofast -march=armv8-a -mtune=cortex-a72 -Wl,z,muldefs -ljemalloc
成绩如下图所示
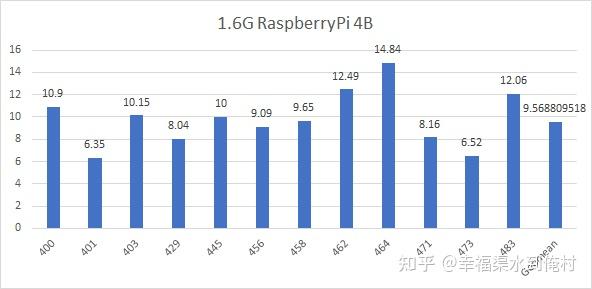
注意,这个A72的IPC比手机里见到的麒麟950高,是因为麒麟950阉割总线和内存,导致IPC不线性。根据这张图的结果,可以估算Tremont J6425可能是29.9分,下一代假设提升32%,就是39.47分。当然,我们还可以根据另外一个处理器的得分进行预估,就是奔腾J4205,这是阿波罗湖的架构,英特尔曾经在官网公布过C3955的成绩,246分,那么1copy就是15.375分,根据A社的估算,16copies和1copy的折损大概是20%,也就是说,J4205的1copy应该是20.8分。则J6425是39.24分,下一代同频预估为51分,很接近Skylake 在ICC 2019的得分了。
这仅仅是一个估算。SPEC2006已经退役,并且负载年代久远,存在明显硬伤。所以最终以官方公布的SPECCPU 2017成绩为准。
需要说明的是,不同的系统配置可能导致不一样的性能,例如同样是A72,AWS G1通过不同的编译器,使得发生如下变化,数据来自anandtech,gcc9.2。
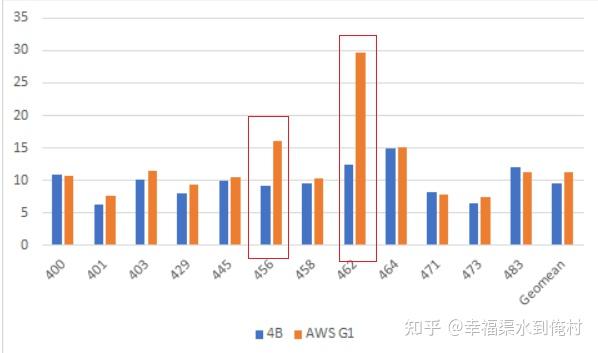
柱状图折算到ISO frequency。可能有非线性误差,结果仅供参考。不过臭名昭著的456和462赫然在列。
9月份更新
随着Gracemont架构的公布,给出了一组数据,即,同工艺的情况下,在gcc编译器下,达成相同整数性能时,Gracemont仅消耗不到40%的Skylake的功耗,那么其实我们马上就可以估计Gracemont的能耗比了。7代14纳米+工艺下,3.4G的Skylake架构,在gcc8.3下带有jemalloc的情况下,SPECint2006可以跑到41分,此时功耗约为10瓦,则相同工艺下,GCM不到4瓦功耗,考虑到intel 10SF能耗比翻倍。intel 7继续改善15%的能耗比。GCM在跑41分的时候,可能也就一瓦多的功耗。
2022年4月更新:
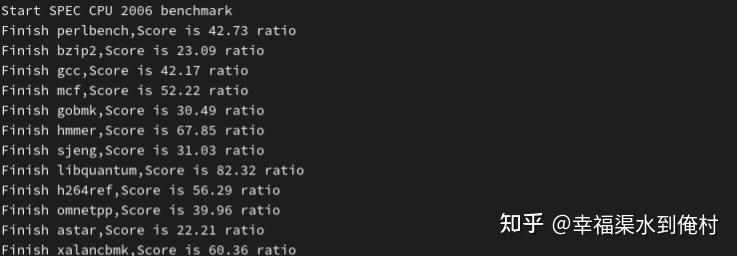
Gracemont的SPEC INT 2017已经测过了,比Zen2高了7%。不过今天看到之前预测的2006的成绩,就放一下实测结果,填一下坑吧
编译器 gcc12
编译选项 -Ofast -march=core-avx2
C++部分添加 -ljemalloc
处理器频率 3.3GHz,得分42.47,算是符合我的预测了。不过跑2006就没有跑2017那么神勇了。
还没上市的的东西没有评价,只有预测。
个人是很期待的,但这不代表我觉得这东西值得买。
初代大小核普遍表现一般,软件适配也是个问题。但这是个良好的开端,是成功的开始。
这个小核的性能功耗指标是不用太担心的,小核走的路相当于重新走一遍过去的研发之路,当然会走的更好。但与大核心的配合水平就有点难以保证了。
个人觉得这个开始实在太晚了,毕竟初代atom是十几年前的事了,比ARM公版初代大小核A15 A7早很多。
英特尔在32nm时代就有以相当低成本实现大小核的客观条件。
如果那时候就尝试大小核就好了

