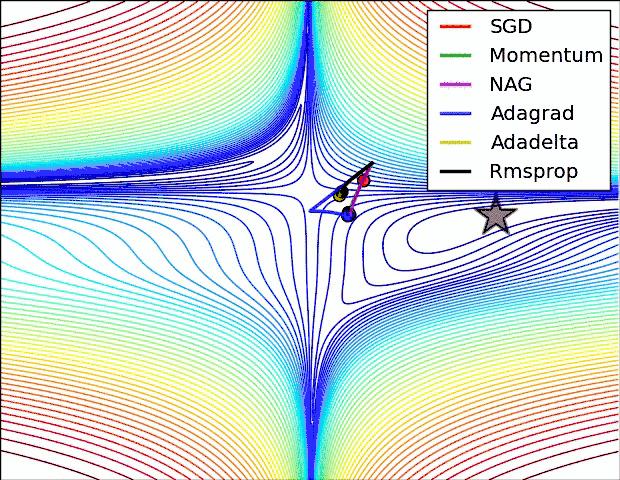
.Adam(),在上一篇实现卷积神经网络CNN的代码分析中也提到了优化器的概念,那么优化器如何通俗的理解呢?


alpha * ΔT是一个很小的值,因为梯度下降时候学习率太大也就是步子太大会错过最优点所以一般设置学习率都比较小(即使会导致下降的很慢但是不容易错过最优解呀),那么这就决定了上面的乘积结果不会太大,我们就近似得到未来位置的W值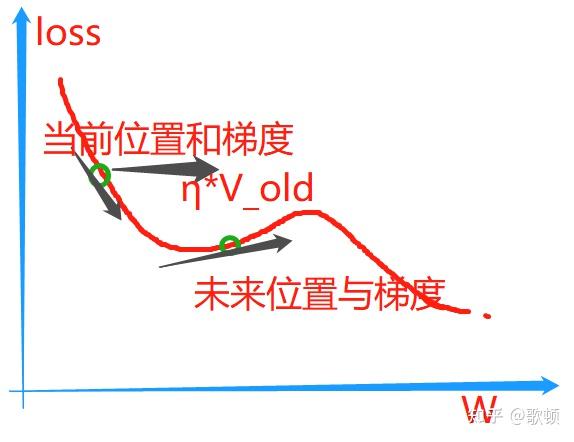
.SGD函数中了class torch.optim.SGD(params, lr=, momentum=0, dampening=0, weight_decay=0, nesterov=False)[source]
α/分母这一部分决定,ε为一个超级小的数来防止分母为0的)torch.optim.Adagrad(params, lr=0.01, lr_decay=0, weight_decay=0, initial_accumulator_value=0)



torch.optim.RMSprop(params, lr=0.01, alpha=0.99, eps=1e-08, weight_decay=0, momentum=0, centered=False)

torch.optim.Adadelta(params, lr=1.0, rho=0.9, eps=1e-06, weight_decay=0)


torch.optim.Adam(params, lr=0.001, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, amsgrad=False)


torch.optim.NAdam(params, lr=0.002, betas=(0.9, 0.999), eps=1e-08, weight_decay=0, momentum_decay=0.004)