

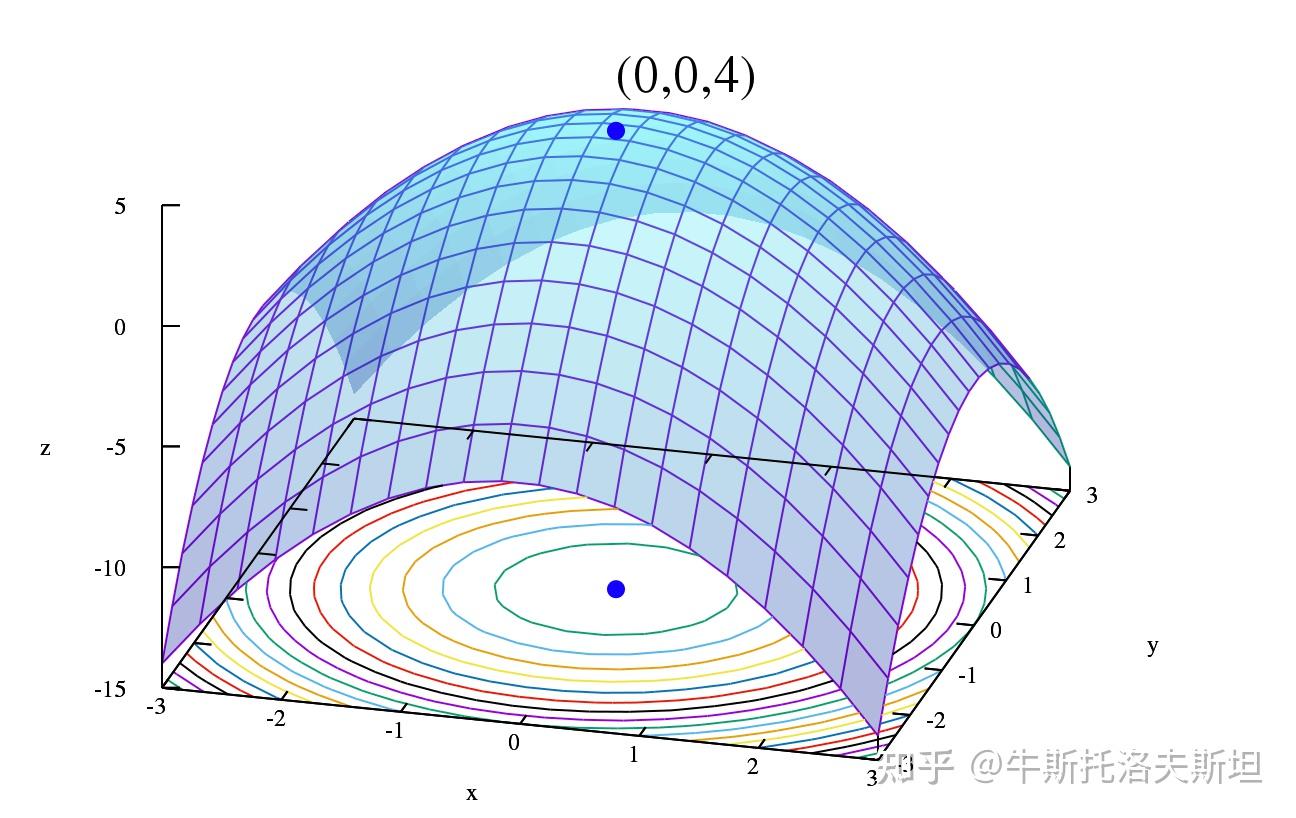
约束优化问题在实际应用极其广泛,因为在实际问题中往往都存在诸多现实约束。约束优化考虑如下问题: 与无约束问题不同,约束优化问题中自变量不能任意取值,这导致许多无约束优化算法不能直接使用。例如梯度法中沿着负梯度方向下降所得的点未必是可行点,要寻找的最优解处目标函数的梯度也不是零向量。这使得约束优化问题比无约束优化问题要复杂许多。放张很漂亮的等高线图如下:
考虑一种简单的情况,假设问题约束中仅含等式约束,即考虑问题: 其中
为等式约束的指标集,
为连续函数。
罚函数法的思想是将约束优化问题式(2) 转化为无约束优化问题来进行求解。为了保证解的逼近质量,无约束优化问题的目标函数为原约束优化问题的目标函数加上与约束函数有关的惩罚项。对于可行域外的点,惩罚项为正,即对该点进行惩罚;对于可行域内的点,惩罚项为0,即不做任何惩罚。因此,惩罚项会促使无约束优化问题的解落在可行域内。
等式约束的二次罚函数:对优化问题式(2)定义二次惩罚函数如下 这种罚函数对不满足约束的点进行惩罚,在迭代过程中点列一般处于可行域之外,因此它也被称为外点罚函数。
二次罚函数的特点如下:对于非可行点而言,当变大时,惩罚项在罚函数中的权重加大,对罚函数求极小,相当于迫使其极小点向可行域靠近;在可行域中,惩罚函数的全局极小点与约束最优化问题式(2) 的最优解相同。
举例:考虑如下优化问题及其对应的二次惩罚函数如下 容易求得最优解为
,下图给出了不同惩罚因子对用的二次罚函数的等高线图。
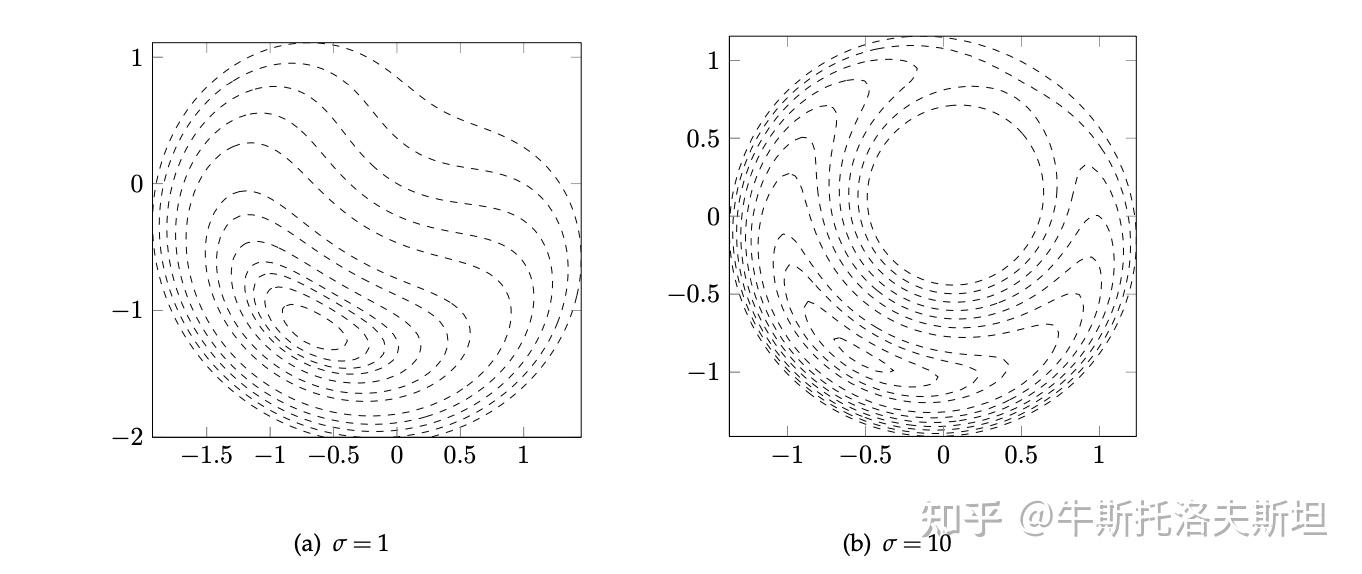
可以看出随惩罚因子的增大,罚函数的最小值与原问题的最小值越来越接近。但最优点附近的等高线越来越趋于扁平,这导致求解无约束优化问题的难度变大。在实际情况可能由于惩罚因子过小时,罚函数可能无下界,主要原因不可行点处的函数下降抵消了罚函数对约束违反的惩罚。实际上所有外点罚函数法均存在这个问题,因此惩罚因子的初值选取不应该太小。
二次罚函数算法的流程如下图所示。

不等式约束优化问题有如下形式: 不等式约束的二次罚函数: 只对
的点进行惩罚,定义如下:
注意上式可以利用梯度(可导)进行求解,但一般不是二阶可导的,不能直接利用二阶算法(牛顿法)求解子问题。
一般约束的二次罚函数:对于同时包含不等式与等式约束的优化问题,定义罚函数如下 只需要将两种约束的罚函数相加就能得到一般约束优化问题的二次罚函数。
前面介绍的二次罚函数均属于外点罚函数,即在求解过程中允许自变量位于原问题可行域之外,当罚因子趋于无穷时,子问题最优解序列从可行域外部逼近最优解。自然地,如果想要使得子问题最优解序列从可行域内部逼近最优解,则需要构造内点罚函数。顾名思义,内点罚函数在迭代时始终要求自变量不能违反约束,因此它主要用于不等式约束优化问题。
考虑含不等式约束的优化问题式(5),为了使得迭代点始终在可行域内,当迭代点趋于可行域边界时,我们需要罚函数趋于正无穷,常用的罚函数是对数罚函数。
对数罚函数:对于不等式约束最优化问题,定义对数罚函数如下: 对数罚函数的极小值严格位于可行域内部。原问题最优解通常位于可行域边界,此时需要调整惩罚因子使其趋近于0,这会减弱对数罚函数在边界附近的惩罚效果。
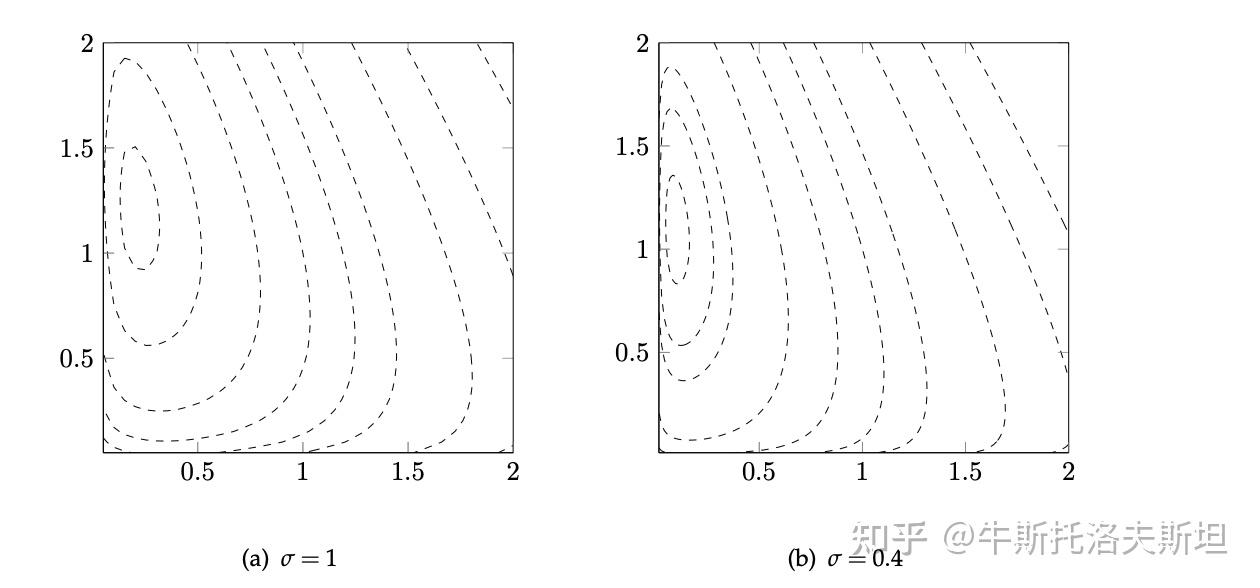
实例: 考虑如下优化问题及其对应的对数罚函数如下 不同惩罚因子对应的罚函数的等高线如下图所示,可以看出,随着惩罚因子的减小,对数罚函数的最小值点和原问题最小值点越来越接近,但当变量趋于可行域边界时,对数罚函数趋于无穷大。
对数罚函数方法对应计算流程图如下所示。

和二次罚函数法不同,对数罚函数算法要求初始点为一个可行解,这是根据对数罚函数法本身的要求。常见的收敛准则可以为: 实际以上算法的迭代点序列满足下式:
同样地,内点罚函数法也会有类似外点罚函数法的数值困难,即当惩罚因子趋于0时,罚函数的海森矩阵条件数趋于无穷大,因此子问题的求解将会越来越困难。
前面介绍的罚函数方法一个共同特点就是在求解的时候必须令罚因子趋于正无穷或零,这会带来一定的数值困难。而对于有些罚函数,在问题求解时不需要令罚因子趋于正无穷(或零),这种罚函数称为精确罚函数。
精确罚函数:罚因子选取适当,对罚函数进行极小化得到的解恰好就是原问题的精确解。这个性质在设计算法时非常有用,使用精确罚函数的算法通常会有比较好的性质。
?1罚函数:对应一般约束最优化问题,定义为 对于精确罚函数,当罚因子充分大(不需要是正无穷)时,原问题的极小值点就是?1 罚函数的极小值点。
增广拉格朗日函数法的每一步构造一个增广拉格朗日函数,而该函数的构造依赖于拉格朗日函数和约束的二次罚函数。对于等式约束优化问题,增广拉格朗日函数定义为 在拉格朗日函数的基础上,添加约束的二次罚函数。对于等式约束优化问题,最优解与最优乘子具有以下关系:
增广拉格朗日函数法计算流程如下图所示。

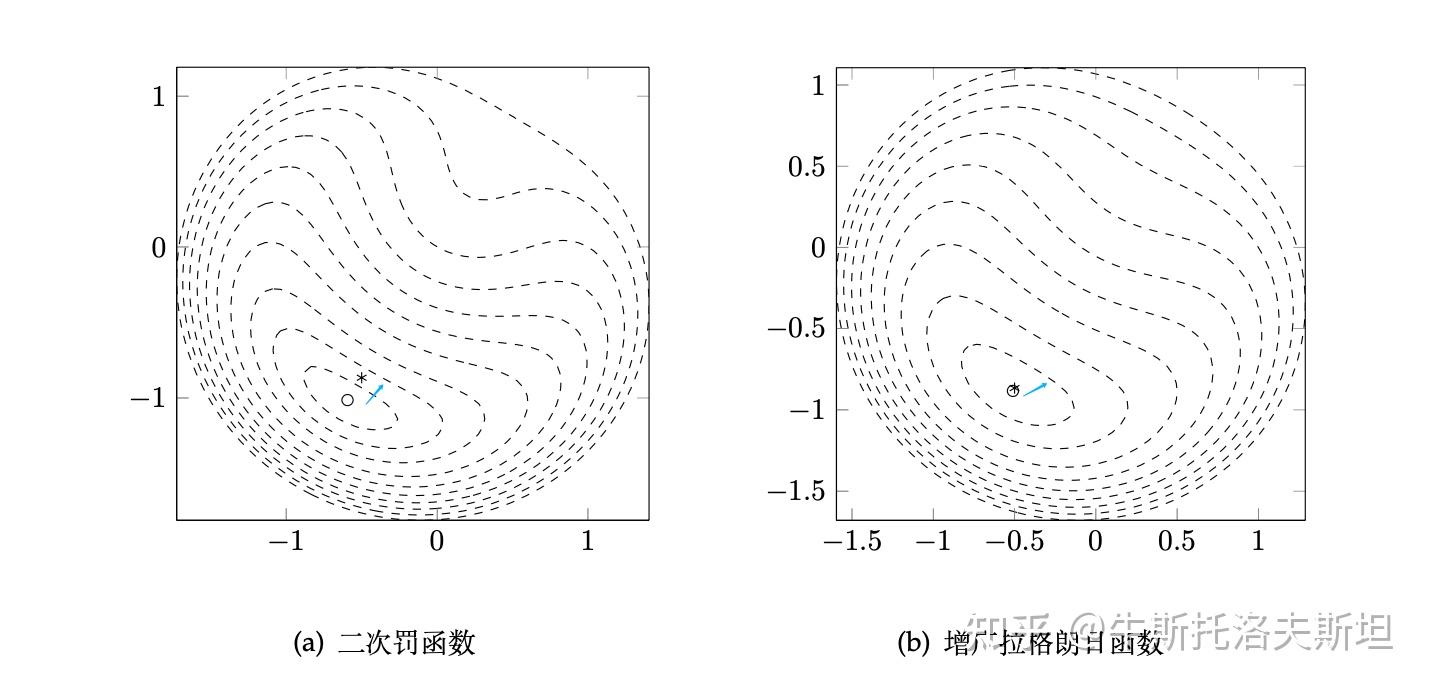
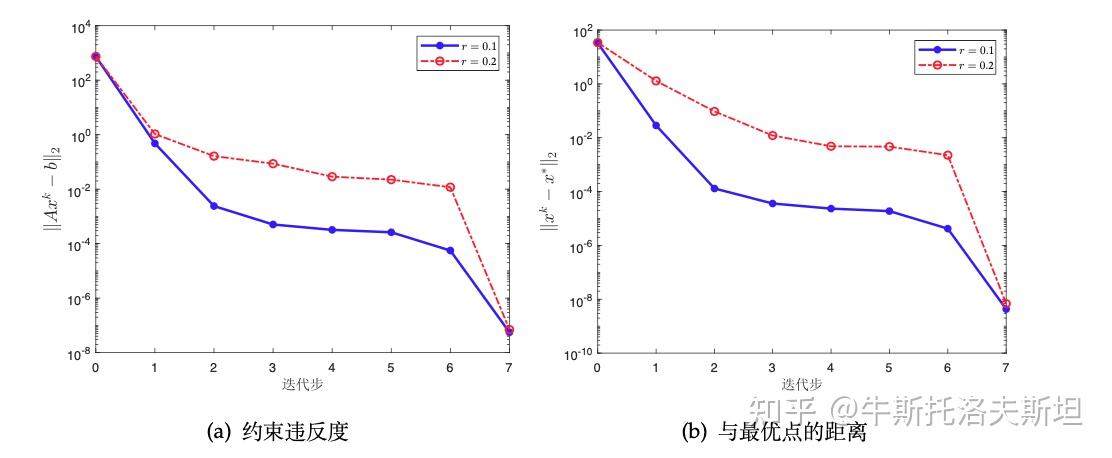
实例:考虑式(4)优化问题,对应的增广拉格朗日函数如下: 增广朗日函数法与二次罚函数法求解的点与最优点的位置关系如下图所示,可以得出前者得到解更接近于最优解,即说明增广朗日函数法相较于二次罚函数法在控制约束违反度上的优越性。
考虑一般约束优化问题如下: 对于带不等式约束的优化问题,先通过引入松弛变量将不等式约束转化为等式约束和简单的非负约束,再对保留非负约束形式的拉格朗日函数添加等式约束的二次罚函数来构造增广拉格朗日函数。
通过引入松弛变量可以得到如下等价形式: 保留非负约束,可以构造拉格朗日函数:
式(17)中等式约束的二次罚函数为
构造增广拉格朗日函数如下:
增广拉格朗日函数法: 通过增广拉格朗日函数,求解如下问题
求解上述问题的一个有效的方法是投影梯度法;另外一种方法是消去
,求解只关于
的优化问题,固定
,关于
的子问题可以表示为
根据凸优化问题的最优性理论,
为以上问题的一个全局最优解,当且仅当
将上式代入增广拉格朗日函数为
其为关于x 的连续可微函数(
连续可微),式(22)等价于
并可以利用梯度法进行求解。
对于式(17),其最优解需满足KKT条件如下: 式(21)最优解
满足下式:
可以计算乘子的更新公式如下:
至此,给出约束优化问题的增广拉格朗日函数法及其对应的参数更新方式。
考虑凸优化问题如下: 其中
,
为闭凸函数。
其增广拉格朗日函数为: 上式对应增广拉格朗日函数法更新公式为
式(31)的增广拉格朗日函数法计算流程如下所示。

考虑BP问题如下: 引入拉格朗日乘子,得到拉格朗日函数为
其对偶函数为
因此,得到如下对偶问题
原始问题的增广拉格朗日函数法迭代更新公式如下:
对于BP 问题,固定的σ 也可以保证增广拉格朗日函数法收敛,如下图所示。
引入松弛变量,原始问题的对偶问题式(37)可以等价写成: 引入拉格朗日乘子和罚因子,增广拉格朗日函数为
其迭代公式如下所示:
消去
的增广增广拉格朗日函数法为:
其中:
半正定规划(Semidefinite programming,SDP)是凸优化问题的一个分支,它具有线性目标函数(由用户指定的最大化或最小化函数),且其定义在半正定矩阵构成的凸锥与仿射空间的交集上,即光谱面。
半正定规划问题如下: 其对偶问题为
对于原始问题,增广拉格朗日函数为
其中:
那么,增广拉格朗日函数法为
其对偶问题对应的增广拉格朗日函数法为:
其中
为到半定锥集
投影算子。
线性规划是非常经典的约束优化问题,它的目标函数和约束都是线性函数。因为其形式简单,在现实中有非常多的应用,线性规划一直受到人们的格外关注。求解线性规划问题的算法非常之多,最经典的要数Dantzig 在1947 年提出的单纯形法。由于线性规划问题具有特殊结构,它的解必然是在可行域的顶点(或某一边界处)取到,而单纯形法则是通过某种方式不断列出可行域的顶点然后一步一步寻找问题的最优解。由于线性规划可行域的顶点数可能多达个(n 为自变量维数),因此单纯形法最坏情况下的复杂度是指数量级。实际上我们也可以构造出特殊的例子,使得单纯形法遍历可行域中的每一个顶点。这一现象表明对于某些大型问题和病态问题,单纯形法的效果可能很差,我们必须寻找其他办法来求解线性规划问题。
在大约30 年后,内点法应运而生,其中比较实用的算法是Karmarkar在1984 年提出的线性规划算法。内点法是在可行域内部寻找一条路径最终抵达其边界,这和单纯形法有着截然不同的思想。由于迭代点处于可行域内部,因此求解每个子问题的计算代价都远高于仅仅在可行域边界移动的单纯形法。然而内点法的一步迭代对问题解的改善是显著的,正因为如此,可以证明内点法实际上是一个多项式时间算法。
线性规划的原始问题和对偶问题分别如下所示:
对应的KKT条件为 原始– 对偶算法作为一种内点法,它实际上是利用上式条件不断在可行域的相对内部产生迭代点的过程。求解实例如下:
路径追踪算法(Path-Following Algorithms)简要介绍可参考:
https://www.zgbk.com/ecph/words?SiteID=1&ID=221269&Type=bkzyb路径追踪算法详细介绍可参考:
https://richtarik.org/docs/Wright-Ch5-Path-Following-Algorithms.pdf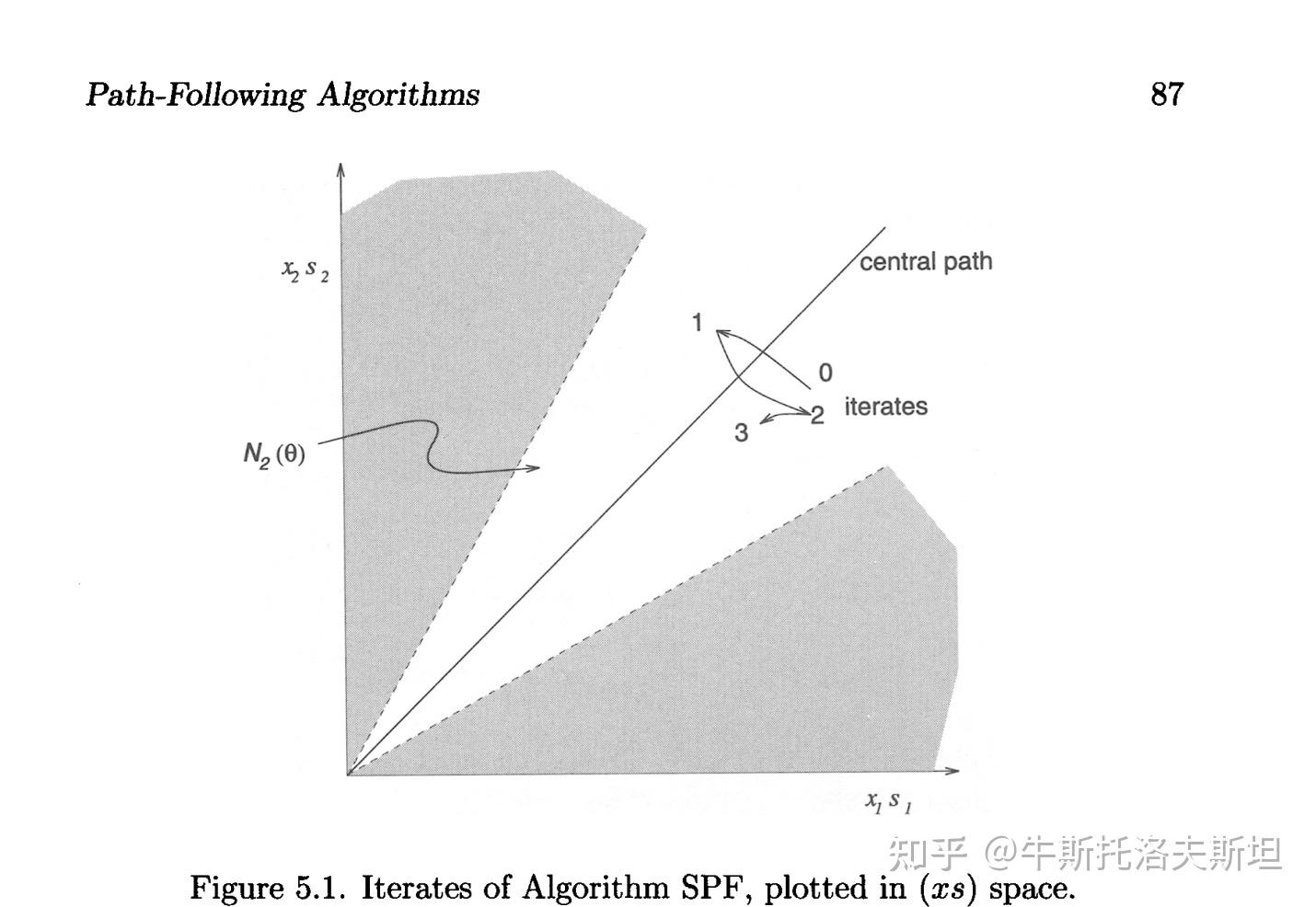
总结了约束优化问题的相关内容。
[1]. 维基百科
[2]. 刘浩洋等《最优化:建模、算法与理论》。

