

优化是应用数学的一个分支,其也是机器学习的核心组成部分
为什么这么说呢,因为实际上,机器学习 = 模型表征 + 模型评估 + 优化算法
举两个例子:
总结来说就是:
优化的目的就是找到一个最优解,让模型表征能够完美的表征对应的数据。而在深度学习过程中,优化问题大多是非凸的,并且数据量极大,因此,很多优化问题并不存在解析解。为了求得最小化目标函数的数值解,我们将通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。
这些优化算法,就是优化器
带着思考:为什么梯度下降算法可能降低目标函数值
以一维梯度下降为例
目标函数:f(x),给定绝对值足够小的数?,根据泰勒展开式,可以得到如下公式:
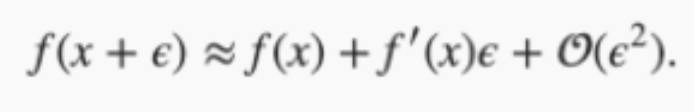 ?
?
其中,由于?足够小,高阶项被省略,因此:
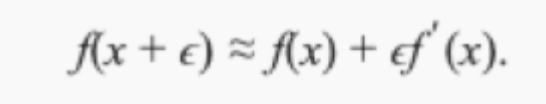
这里f′(x)是函数f在x处的梯度。一维函数时,也就是我们所说的导数
接下来,找到一个常数η>0,使得|ηf′(x)|足够小,那么可以将?替换为?ηf′(x)并得到:
?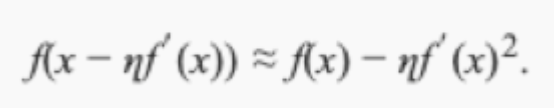
?
这里,如果导数f′(x) ≠?0,那么ηf′(x)^2>0,因此
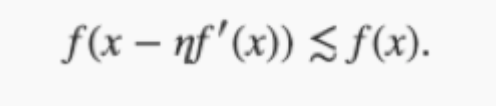
?
这意味这,如果通过 x-ηf′(x)?来迭代x,那么函数值f(x)一定会降低
因此,在梯度下降中,我们的方式就是:选取一个初始值x和常数η>0,然后通过上式不断的迭代x,知道达到停止条件,例如f′(x)^2的值已足够小或迭代次数已达到某个值。
而在深度学习里面,目标函数通常是训练数据集中有关各个样本的损失函数的平均,目标函数定义为:
目标函数在x处的梯度为:
如果使用梯度下降,每次自变量迭代的计算开销为O(n),它随着n线性增长。因此,当训练数据样本数很大时,梯度下降每次迭代的计算开销很高
随机梯度下降:每次迭代,随机均匀采样一个索引样本 i?∈?{1,...,n},计算梯度?fi?(x) 来迭代x
因此,计算开销从O(n)降低到了常数O(1)
而在统计学中,随机梯度是梯度的无偏估计
这意味着,平均来说,随机梯度是对梯度的一个良好的估计
可以发现,SGD发生了少量学习不稳定的情况
因此,实际工作中,各个算法库的SGD 使用的都是这个
同时,在实际应用中,(小批量)随机梯度下降的学习率可以在迭代过程中自我衰减。
在梯度下降中,目标函数有关自变量的梯度代表了目标函数在自变量当前位置下降最快的方向
然而,如果自变量的迭代方向仅仅取决于自变量的当前位置,这可能会带来一些问题
假设,目标函数:
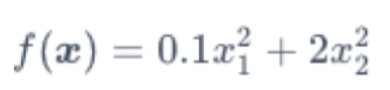
?
注意,这里x1的系数为0.1 而x2的系数为2,
因此,就有了动量法
设时间步t时的自变量为xt,学习率为η
在时间步0,动量法创建初始速度变量v0,并将其元素初始化为0
当t>0是,动量法对每次迭代的步骤做如下修改
其中,gt为小批量随机梯度(f't(x))
动量超参数γ满足0≤γ<1。当γ=0时,动量法等价于小批量随机梯度下降
在解释动量法的数学原理前
可以看到使用较小的学习率η=0.4和动量超参数γ=0.5时,动量法在竖直方向上的移动更加平滑,且在水平方向上更快逼近最优解
使用较大的学习率η=0.6,此时自变量也不再发散
为了从数学上理解动量法,让我们先解释一下指数加权移动平均
由指数加权移动平均的形式可得,动量法实际上就是对vt做了指数加权平均
换句话说:相比较SGD,动量法在各个方向上的移动幅度不仅取决于当前梯度,还取决于对于过去各个梯度在各个方向上是否一致
这样,我们使用较大的学习率,就可以使得自变量向最优解更快移动
在之前的优化算法中,目标函数的自变量的每一个元素都使用同一个学习率来自我迭代。
而在动量法中,我们看到当x1和x2的梯度值有较大差异时,需要选择足够小的学习率让梯度不发散
动量法依赖指数加权平均,从而降低发散的可能
本节的AdaGrad,根据自变量在每个维度上的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应的问题
AdaGrad使用中间变量st,其中gt?代表SGD的梯度,st为元素平方的累加变量,在时间步t,有
接着,将目标函数自变量中每个元素的学习率通过按元素运算重新调整一下:
其中η是学习率,?是为了维持数值稳定性而添加的常数,如10e?6。这里开方、除法和乘法的运算都是按元素运算的。这些按元素运算使得目标函数自变量中每个元素都分别拥有自己的学习率
需要强调的是,小批量随机梯度按元素平方的累加变量st出现在学习率的分母项中
因此,如果目标函数有关自变量中某个元素的偏导数一直都较大,那么该元素的学习率将下降较快
反之,如果目标函数有关自变量中某个元素的偏导数一直都较小,那么该元素的学习率将下降较慢
然而,由于st一直在累加按元素平方的梯度,自变量中每个元素的学习率在迭代过程中一直在降低(或不变)
所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。
目标函数和学习率与动量法相同,实验如下
可以看到,自变量的迭代轨迹较平滑。但由于st?的累加效果使学习率不断衰减,自变量在迭代后期的移动幅度较小。
刚才我们提到,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解
为了解决这一问题,RMSProp算法对AdaGrad算法做了一点小小的修改
RMSProp算法将AdaGrad中的梯度按元素平方做指数加权移动平均
和AdaGrad算法一样,RMSProp算法将目标函数自变量中每个元素的学习率通过按元素运算重新调整,然后更新自变量
因为RMSProp算法的状态变量st?是对平方项gt⊙gt的指数加权移动平均
所以可以看作是最近1/(1?γ)个时间步的小批量随机梯度平方项的加权平均
如此一来,自变量每个元素的学习率在迭代过程中就不再一直降低(或不变)
来看同样的目标函数的RMSProp的结果
看jupyter
可以发现:在同样的学习率下,RMSProp算法可以更快逼近最优解
RMSProp相比较AdaGrad算法在收敛后期迭代更快
除了RMSProp算法以外,另一个常用优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有用解的问题做了改进
AdaDelta算法没有学习率这一超参数
思想是与RMSProp基本一致
与RMSProp算法不同的是,AdaDelta算法还维护一个额外的状态变量Δxt?
使用Δxt?-1来计算自变量的变化量,然后更新自变量
最后,使用Δxt来记录自变量变化量g′t按元素平方的指数加权移动平均
可以看到,如不考虑?的影响,AdaDelta算法跟RMSProp算法的不同之处在于使用sqrt(Δxt?1)来替代学习率η
最稳的算法
思想:在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均?
所以Adam算法可以看做是RMSProp算法与动量法的结合
给定超参数0≤β1?<1(作者建议设置为0.9),时间步t的动量变量vt即小批量随机梯度gt的指数加权移动平均
和RMSProp算法中一样,给定超参数0≤β2<1(算法作者建议设为0.999)
将小批量随机梯度按元素平方后的项gt⊙gt做指数加权移动平均得到st
为了解决0启动问题,在Adam算法中,对变量vt?和st?均作了偏差修正
接下来,Adam算法使用以上偏差修正后的变量vtst,将模型参数中每个元素的学习率通过按元素运算重新调整
其中η是学习率,?是为了维持数值稳定性而添加的常数,如10e?8。和AdaGrad算法、RMSProp算法以及AdaDelta算法一样,目标函数自变量中每个元素都分别拥有自己的学习率
最后,使用g′t?迭代自变量
上图比较了6种优化器收敛到目标点(五角星)的运行过程,从图中可以大致看出:
① 在运行速度方面
② 在收敛轨迹方面
上图在一个存在鞍点的曲面,比较6中优化器的性能表现,从图中大致可以看出:
【1】http://zh.d2l.ai/index.html?李沐老师《动手学深度学习》
【2】Ruder S . An overview of gradient descent optimization algorithms[J]. 2016.
【3】https://blog.csdn.net/weixin_40170902/article/details/80092628
【4】https://www.cnblogs.com/guoyaohua/p/8542554.html
其中,由于?足够小,高阶项被省略,因此:
这里f′(x)是函数f在x处的梯度。一维函数时,也就是我们所说的导数
接下来,找到一个常数η>0,使得|ηf′(x)|足够小,那么可以将?替换为?ηf′(x)并得到:
这里,如果导数f′(x) ≠?0,那么ηf′(x)^2>0,因此
这意味这,如果通过 x-ηf′(x)?来迭代x,那么函数值f(x)一定会降低
因此,在梯度下降中,我们的方式就是:选取一个初始值x和常数η>0,然后通过上式不断的迭代x,知道达到停止条件,例如f′(x)^2的值已足够小或迭代次数已达到某个值
而在深度学习里面,目标函数通常是训练数据集中有关各个样本的损失函数的平均,目标函数定义为:
目标函数在x处的梯度为:
?
如果使用梯度下降,每次自变量迭代的计算开销为O(n),它随着n线性增长。因此,当训练数据样本数很大时,梯度下降每次迭代的计算开销很高
随机梯度下降:每次迭代,随机均匀采样一个索引样本 i?∈?{1,...,n},计算梯度?fi?(x) 来迭代x
因此,计算开销从O(n)降低到了常数O(1)
而在统计学中,随机梯度是梯度的无偏估计
这意味着,平均来说,随机梯度是对梯度的一个良好的估计
看jupyter
可以发现,SGD发生了少量学习不稳定的情况
因此,实际工作中,各个算法库的SGD 使用的都是这个,其计算开销为O(B)
同时,在实际应用中,(小批量)随机梯度下降的学习率可以在迭代过程中自我衰减。
在梯度下降中,目标函数有关自变量的梯度代表了目标函数在自变量当前位置下降最快的方向
然而,如果自变量的迭代方向仅仅取决于自变量的当前位置,这可能会带来一些问题
假设,目标函数:
注意,这里x1的系数为0.1 而x2的系数为2,下面通过代码实现这个目标函数的梯度下降,并查看使用学习率0.4的自变量迭代轨迹
看jupyter
因此,就有了动量法
设时间步t时的自变量为xt,学习率为η
在时间步0,动量法创建初始速度变量v0,并将其元素初始化为0
当t>0是,动量法对每次迭代的步骤做如下修改
其中,gt为小批量随机梯度(f't(x))
动量超参数γ满足0≤γ<1。当γ=0时,动量法等价于小批量随机梯度下降
在解释动量法的数学原理前,先从实验中观察梯度下降在使用动量法后的迭代轨迹
看jupyter
可以看到使用较小的学习率η=0.4和动量超参数γ=0.5时,动量法在竖直方向上的移动更加平滑,且在水平方向上更快逼近最优解
使用较大的学习率η=0.6,此时自变量也不再发散
为了从数学上理解动量法,让我们先解释一下指数加权移动平均
给定超参数0≤γ<1,当前时间步t的变量yt是上一时间步t?1的变量yt?1和当前时间步另一变量xt的线性组合:
对y进行展开
现在,我们对动量法的速度变量做变形:
由指数加权移动平均的形式可得,动量法实际上就是对vt做了指数加权平均
换句话说:相比较SGD,动量法在各个方向上的移动幅度不仅取决于当前梯度,还取决于对于过去各个梯度在各个方向上是否一致
这样,我们使用较大的学习率,就可以使得自变量向最优解更快移动
在之前的优化算法中,目标函数的自变量的每一个元素都使用同一个学习率来自我迭代。
而在动量法中,我们看到当x1和x2的梯度值有较大差异时,需要选择足够小的学习率让梯度不发散
动量法依赖指数加权平均,从而降低发散的可能
本节的AdaGrad,根据自变量在每个维度上的梯度值的大小来调整各个维度上的学习率,从而避免统一的学习率难以适应的问题
AdaGrad使用中间变量st,其中gt?代表SGD的梯度,st为元素平方的累加变量,在时间步t,有
接着,将目标函数自变量中每个元素的学习率通过按元素运算重新调整一下:
其中η是学习率,?是为了维持数值稳定性而添加的常数,如10e?6。这里开方、除法和乘法的运算都是按元素运算的。这些按元素运算使得目标函数自变量中每个元素都分别拥有自己的学习率
需要强调的是,小批量随机梯度按元素平方的累加变量st出现在学习率的分母项中
因此,如果目标函数有关自变量中某个元素的偏导数一直都较大,那么该元素的学习率将下降较快
反之,如果目标函数有关自变量中某个元素的偏导数一直都较小,那么该元素的学习率将下降较慢
然而,由于st一直在累加按元素平方的梯度,自变量中每个元素的学习率在迭代过程中一直在降低(或不变)
所以,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。
目标函数和学习率与动量法相同,实验如下
看jupyter
可以看到,自变量的迭代轨迹较平滑。但由于st?的累加效果使学习率不断衰减,自变量在迭代后期的移动幅度较小。
刚才我们提到,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解
为了解决这一问题,RMSProp算法对AdaGrad算法做了一点小小的修改
RMSProp算法将AdaGrad中的梯度按元素平方做指数加权移动平均
和AdaGrad算法一样,RMSProp算法将目标函数自变量中每个元素的学习率通过按元素运算重新调整,然后更新自变量
因为RMSProp算法的状态变量st?是对平方项gt⊙gt的指数加权移动平均
所以可以看作是最近1/(1?γ)个时间步的小批量随机梯度平方项的加权平均
如此一来,自变量每个元素的学习率在迭代过程中就不再一直降低(或不变)
来看同样的目标函数的RMSProp的结果
看jupyter
可以发现:在同样的学习率下,RMSProp算法可以更快逼近最优解
RMSProp相比较AdaGrad算法在收敛后期迭代更快
除了RMSProp算法以外,另一个常用优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有用解的问题做了改进
AdaDelta算法没有学习率这一超参数
思想是与RMSProp基本一致
与RMSProp算法不同的是,AdaDelta算法还维护一个额外的状态变量Δxt?
使用Δxt?-1来计算自变量的变化量,然后更新自变量
最后,使用Δxt来记录自变量变化量g′t按元素平方的指数加权移动平均
可以看到,如不考虑?的影响,AdaDelta算法跟RMSProp算法的不同之处在于使用sqrt(Δxt?1)来替代学习率η
最稳的算法
思想:在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均?
所以Adam算法可以看做是RMSProp算法与动量法的结合
给定超参数0≤β1?<1(作者建议设置为0.9),时间步t的动量变量vt即小批量随机梯度gt的指数加权移动平均
和RMSProp算法中一样,给定超参数0≤β2<1(算法作者建议设为0.999)
将小批量随机梯度按元素平方后的项gt⊙gt做指数加权移动平均得到st
为了解决0启动问题,在Adam算法中,对变量vt?和st?均作了偏差修正
接下来,Adam算法使用以上偏差修正后的变量vtst,将模型参数中每个元素的学习率通过按元素运算重新调整
其中η是学习率,?是为了维持数值稳定性而添加的常数,如10e?8。和AdaGrad算法、RMSProp算法以及AdaDelta算法一样,目标函数自变量中每个元素都分别拥有自己的学习率
最后,使用g′t?迭代自变量
结束了枯燥的理论分析,我们来看一下可视化效果
上图比较了6种优化器收敛到目标点(五角星)的运行过程,从图中可以大致看出:
① 在运行速度方面
② 在收敛轨迹方面
上图在一个存在鞍点的曲面,比较6中优化器的性能表现,从图中大致可以看出:
【1】http://zh.d2l.ai/index.html?李沐老师《动手学深度学习》
【2】Ruder S . An overview of gradient descent optimization algorithms[J]. 2016.
【3】https://blog.csdn.net/weixin_40170902/article/details/80092628

