最优化问题的分类
1)无约束和有约束条件;
2)确定性和随机性最优问题(变量是否确定);
3)线性优化与非线性优化(目标函数和约束条件是否线性);
4)静态规划和动态规划(解是否随时间变化)。
使多个目标在给定区域同时尽可能最佳,多目标优化的解通常是一组均衡解(即一组由众多 Pareto最优解组成的最优解集合 ,集合中的各个元素称为 Pareto最优解或非劣最优解)。
①非劣解——多目标优化问题并不存在一个最优解,所有可能的解都称为非劣解,也称为Pareto解。
②Pareto最优解——无法在改进任何目标函数的同时不削弱至少一个其他目标函数。这种解称作非支配解或Pareto最优解。
多目标优化问题不存在唯一的全局最优解 ,过多的非劣解是无法直接应用的 ,所以在求解时就是要寻找一个最终解。
(1)求最终解主要有三类方法:
一是求非劣解的生成法,即先求出大量的非劣解,构成非劣解的一个子集,然后按照决策者的意图找出最终解;(生成法主要有加权法﹑约束法﹑加权法和约束法结合的混合法以及多目标遗传算法)
二为交互法,不先求出很多的非劣解,而是通过分析者与决策者对话的方式,逐步求出最终解;
三是事先要求决策者提供目标之间的相对重要程度,算法以此为依据,将多目标问题转化为单目标问题进行求解。
(2)多目标优化算法归结起来有传统优化算法和智能优化算法两大类。
传统优化算法包括加权法、约束法和线性规划法等,实质上就是将多目标函数转化为单目标函数,通过采用单目标优化的方法达到对多目标函数的求解。
线性加权求和法——对多目标优化问题中的N个目标按其重要程度赋以适当的权系数,其乘积和作新的目标函数,再求最优解。
智能优化算法包括进化算法(Evolutionary Algorithm, 简称EA)、粒子群算法(Particle Swarm Optimization, PSO)等。
两者的区别——传统优化技术一般每次能得到Pareo解集中的一个,而用智能算法来求解,可以得到更多的Pareto解,这些解构成了一个最优解集,称为Pareto最优解(任一个目标函数值的提高都必须以牺牲其他目标函数值为代价的解集)。
①MOEA通过对种群 X ( t)执行选择、交叉和变异等操作产生下一代种群 X ( t + 1) ;
②在每一代进化过程中 ,首先将种群 X ( t)中的所有非劣解个体都复制到外部集 A ( t)中;
③然后运用小生境截断算子剔除A ( t)中的劣解和一些距离较近的非劣解个体 ,以得到个体分布更为均匀的下一代外部集 A ( t + 1) ;
④并且按照概率 pe从 A ( t + 1)中选择一定数量的优秀个体进入下代种群;
⑤在进化结束时 ,将外部集中的非劣解个体作为最优解输出。
小生境技术——将每一代个体划分为若干类,每个类中选出若干适应度较大的个体作为一个类的优秀代表组成一个群,再在种群中,以及不同种群中之间,杂交,变异产生新一代个体群。同时采用预选择机制和排挤机制或分享机制完成任务。
基于共享机制的小生境实现方法——通过反映个体之间的相似程度的共享函数来调节群体中各个个体的适应度,从而在这以后的群体进化过程中,算法能够依据这个调整后的新适应度来进行选择运算,以维持群体的多样性,创造出小生境的进化环境。
共享函数——表示群体中两个个体之间密切关系程度的一个函数
共享度是某个个体在群体中共享程度的一中度量,它定义为该个体与群体内其它各个个体之间的共享函数值之和,用S 表示:
S = (i=1,… ,M)
在计算出了群体中各个个体的共享度之后,依据下式来调整各个个体的适应度:
F(X) =F(X) / S (i=1,… ,M)
小生境算法的描述如下:
(1)设置进化代数计数器;随机生成M个初始群体P(t),并求出各个个体的适应度F (i=1,2,M)。
(2)依据各个个体的适应度对其进行降序排列,记忆前N个个体(N小于M)。
(3)选择算法。对群体P(t)进行比例选择运算,得到P (t)。
(4)交叉选择。对选择的个体集合P (t) 作单点交叉运算,得到P (t)。
(5)变异运算。对P (t)作均匀变异运算,得到P (t)。
(6)小生境淘汰运算。将第(5)步得到的M个个体和第(2)步所记忆的N个个体合并在一起,得到一个含有M+N 个个体的新群体;对着M+N个个体,按照下式得到两个个体x 和x 之间的海明距离:|| x - x ||= d,当|| x - x ||小于L时,比较个体x 和个体x 的适应度大小,并对其中适应度较低的个体处以罚函数: Fmin(x,x )=Penalty。
(7)依据这M+N个个体的新适应度对各个个体进行降序排列,记忆前N个个体。
(8)终止条件判断。若不满足终止条件,则:更新进化代数记忆器t = t+1, 并将第(7)步排列中的前M个个体作为新的下一代群体P(t),然后转到第(3)步:若满足终止条件,则:输出计算结果,算法结束。
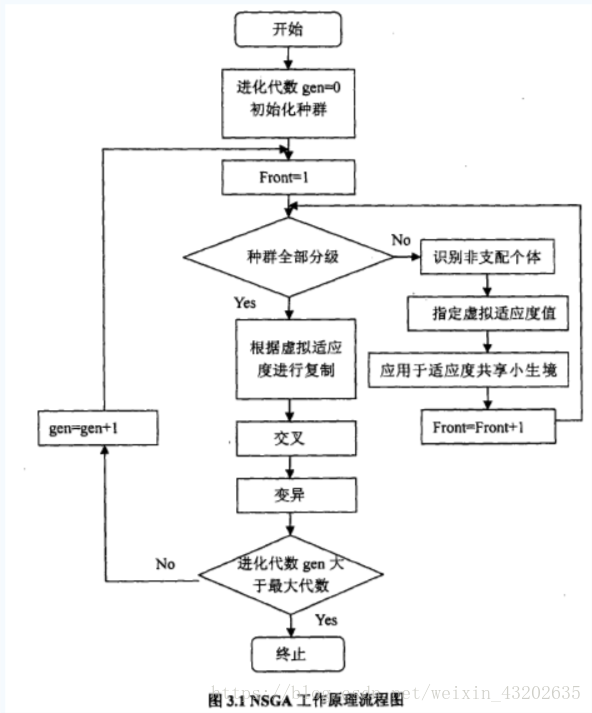
NSGA使用了非支配分层方法和适应度共享策略。非支配分层方法可以使好的个体有更大的机会遗传到下一代;适应度共享策略则使得准Pareto面上的个体均匀分布,保持了群体多样性,克服了超级个体的过度繁殖,防止了早熟收敛。
NSGA与简单的遗传算法的主要区别在于:该算法在选择算子执行之前根据个体之间的支配关系进行了分层。其选择算子、交叉算子和变异算子与简单遗传算法没有区别。
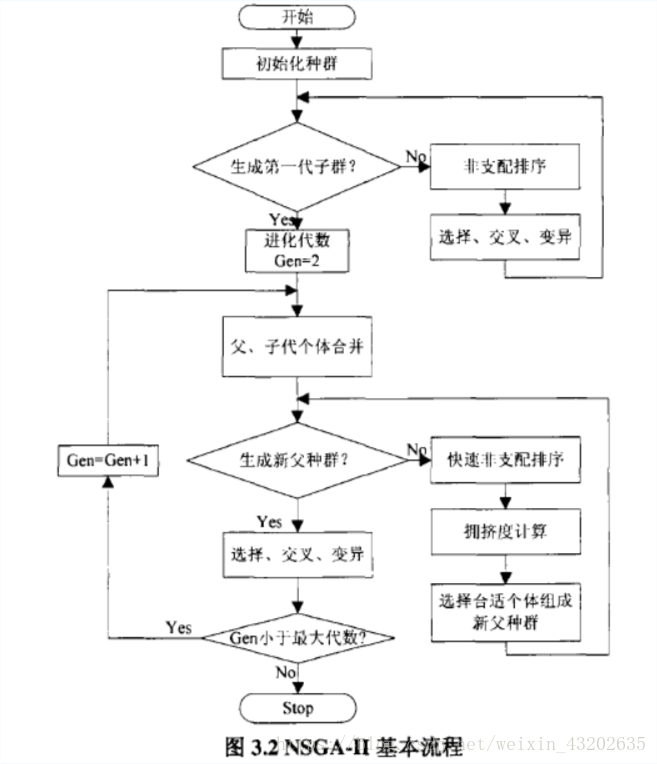
NSGA一II算法的基本思想:
(1)首先,随机产生规模为N的初始种群,非支配排序后通过遗传算法的选择、交叉、变异三个基本操作得到第一代子代种群;
(2)其次,从第二代开始,将父代种群与子代种群合并,进行快速非支配排序,同时对每个非支配层中的个体进行拥挤度计算,根据非支配关系以及个体的拥挤度选取合适的个体组成新的父代种群;
(3)最后,通过遗传算法的基本操作产生新的子代种群:依此类推,直到满足程序结束的条件。
非支配排序算法:
考虑一个目标函数个数为K(K>1)、规模大小为N的种群,通过非支配排序算法可以对该种群进行分层,具体的步骤如下:
通过上述步骤得到的非支配个体集是种群的第一级非支配层;
然后,忽略这些标记的非支配个体,再遵循步骤(1)一(4),就会得到第二级非支配层;
依此类推,直到整个种群被分类。
快速非支配排序算法:
拥挤度——指种群中给定个体的周围个体的密度,直观上可表示为个体。
拥挤度比较算子:
设想这么一个场景:一群鸟进行觅食,而远处有一片玉米地,所有的鸟都不知道玉米地到底在哪里,但是它们知道自己当前的位置距离玉米地有多远。那么找到玉米地的最佳策略,也是最简单有效的策略就是是搜寻目前距离玉米地最近的鸟群的周围区域。
基本粒子群算法:
粒子群由 n个粒子组成 ,每个粒子的位置 xi 代表优化问题在 D维搜索空间中潜在的解;
粒子在搜索空间中以一定的速度飞行 , 这个速度根据它本身的飞行经验和同伴的飞行经验来动态调整下一步飞行方向和距离;
所有的粒子都有一个被目标函数决定的适应值(可以将其理解为距离“玉米地”的距离) , 并且知道自己到目前为止发现的最好位置 (个体极值 pi )和当前的位置 ( xi ) 。
粒子群算法的数学描述 :
每个粒子 i包含为一个 D维的位置向量 xi = ( xi1, xi2, …, xiD )和速度向量 vi = ( vi1, vi2,…, viD ) ,粒子 i搜索解空间时 ,保存其搜索到的最优经历位置pi = ( pi1, pi2, …, piD ) 。在每次迭代开始时 ,粒子根据自身惯性和经验及群体最优经历位置 pg = ( pg1, pg2, …, pgD )来调整自己的速度向量以调整自身位置。
粒子群算法基本思想:
(1)初始化种群后 ,种群的大小记为 N。基于适应度支配的思想 ,将种群划分成两个子群 ,一个称为非支配子集 A,另一个称为支配子集 B ,两个子集的基数分别为 n1、n2 。
(2)外部精英集用来存放每代产生的非劣解子集 A,每次迭代过程只对 B 中的粒子进行速度和位置的更新 ;
(3)并对更新后的 B 中的粒子基于适应度支配思想与 A中的粒子进行比较 ,若 xi ∈B , ? xj ∈A,使得 xi 支配 xj,则删除 xj,使 xi 加入 A 更新外部精英集 ;且精英集的规模要利用一些技术维持在一个上限范围内 ,如密度评估技术、分散度技术等。
(4)最后 ,算法终止的准则可以是最大迭代次数 Tmax、计算精度ε或最优解的最大凝滞步数 Δt等。