

1.概述
在工作中总结Hive的常用优化手段和在工作中使用Hive出现的问题。下面开始本篇文章的优化介绍。
2.介绍
首先,我们来看看Hadoop的计算框架特性,在此特性下会衍生哪些问题?
面对这些问题,我们能有哪些有效的优化手段呢?下面列出一些在工作有效可行的优化手段:
而接下来,我们心中应该会有一些疑问,影响性能的根源是什么?
3.性能低下的根源
hive性能优化时,把HiveQL当做M/R程序来读,即从M/R的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码的替换层面。
RAC(Real Application Cluster)真正应用集群就像一辆机动灵活的小货车,响应快;Hadoop就像吞吐量巨大的轮船,启动开销大,如果每次只做小数量的输入输出,利用率将会很低。所以用好Hadoop的首要任务是增大每次任务所搭载的数据量。
Hadoop的核心能力是parition和sort,因而这也是优化的根本。
观察Hadoop处理数据的过程,有几个显著的特征:
最后得出的结论是:避实就虚,用 job 数的增加,输入量的增加,占用更多存储空间,充分利用空闲 CPU 等各种方法,分解数据倾斜造成的负担。
4.配置角度优化
我们知道了性能低下的根源,同样,我们也可以从Hive的配置解读去优化。Hive系统内部已针对不同的查询预设定了优化方法,用户可以通过调整配置进行控制, 以下举例介绍部分优化的策略以及优化控制选项。
4.1列裁剪
Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。 例如,若有以下查询:
在实施此项查询中,Q 表有 5 列(a,b,c,d,e),Hive 只读取查询逻辑中真实需要 的 3 列 a、b、e,而忽略列 c,d;这样做节省了读取开销,中间表存储开销和数据整合开销。
裁剪所对应的参数项为:hive.optimize.cp=true(默认值为真)
4.2分区裁剪
可以在查询的过程中减少不必要的分区。 例如,若有以下查询:
查询语句若将“subq.prtn=100”条件放入子查询中更为高效,可以减少读入的分区 数目。 Hive 自动执行这种裁剪优化。
分区参数为:hive.optimize.pruner=true(默认值为真)
4.3JOIN操作
在编写带有 join 操作的代码语句时,应该将条目少的表/子查询放在 Join 操作符的左边。 因为在 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,载入条目较少的表 可以有效减少 OOM(out of memory)即内存溢出。所以对于同一个 key 来说,对应的 value 值小的放前,大的放后,这便是“小表放前”原则。 若一条语句中有多个 Join,依据 Join 的条件相同与否,有不同的处理方法。
4.3.1JOIN原则
在使用写有 Join 操作的查询语句时有一条原则:应该将条目少的表/子查询放在 Join 操作符的左边。原因是在 Join 操作的 Reduce 阶段,位于 Join 操作符左边的表的内容会被加载进内存,将条目少的表放在左边,可以有效减少发生 OOM 错误的几率。对于一条语句中有多个 Join 的情况,如果 Join 的条件相同,比如查询:
如果 Join 的条件不相同,比如:
Map-Reduce 的任务数目和 Join 操作的数目是对应的,上述查询和以下查询是等价的:
4.4MAP JOIN操作
Join 操作在 Map 阶段完成,不再需要Reduce,前提条件是需要的数据在 Map 的过程中可以访问到。比如查询:
可以在 Map 阶段完成 Join,如图所示:
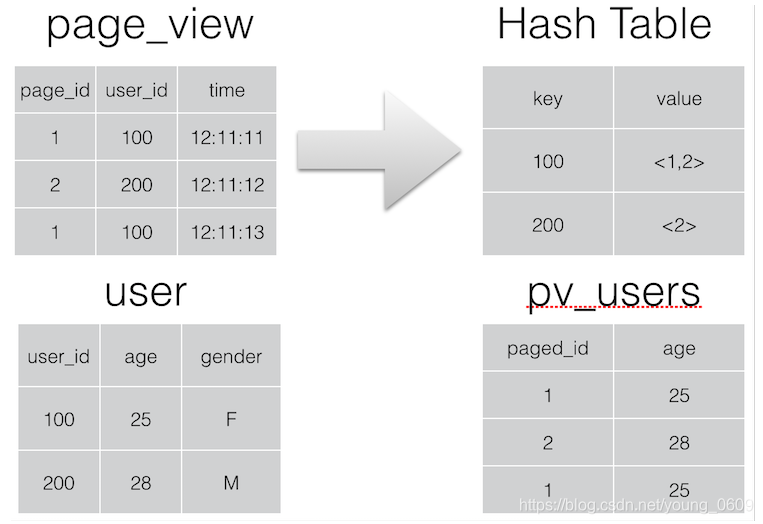
相关的参数为:
4.5GROUP BY操作
进行GROUP BY操作时需要注意一下几点:
事实上并不是所有的聚合操作都需要在reduce部分进行,很多聚合操作都可以先在Map端进行部分聚合,然后reduce端得出最终结果。
这里需要修改的参数为:
hive.map.aggr=true(用于设定是否在 map 端进行聚合,默认值为真) hive.groupby.mapaggr.checkinterval=100000(用于设定 map 端进行聚合操作的条目数)
此处需要设定 hive.groupby.skewindata,当选项设定为 true 是,生成的查询计划有两 个 MapReduce 任务。在第一个 MapReduce 中,map 的输出结果集合会随机分布到 reduce 中, 每个 reduce 做部分聚合操作,并输出结果。这样处理的结果是,相同的 Group By Key 有可 能分发到不同的 reduce 中,从而达到负载均衡的目的;第二个 MapReduce 任务再根据预处 理的数据结果按照 Group By Key 分布到 reduce 中(这个过程可以保证相同的 Group By Key 分布到同一个 reduce 中),最后完成最终的聚合操作。
4.6合并小文件
我们知道文件数目小,容易在文件存储端造成瓶颈,给 HDFS 带来压力,影响处理效率。对此,可以通过合并Map和Reduce的结果文件来消除这样的影响。
用于设置合并属性的参数有:
5.程序角度优化
5.1熟练使用SQL提高查询
熟练地使用 SQL,能写出高效率的查询语句。
场景:有一张 user 表,为卖家每天收到表,user_id,ds(日期)为 key,属性有主营类目,指标有交易金额,交易笔数。每天要取前10天的总收入,总笔数,和最近一天的主营类目。 解决方法 1
如下所示:常用方法
下面给出方法1的思路,实现步骤如下:
第一步:利用分析函数,取每个 user_id 最近一天的主营类目,存入临时表 t1。
第二步:汇总 10 天的总交易金额,交易笔数,存入临时表 t2。
第三步:关联 t1,t2,得到最终的结果。
解决方法 2
如下所示:优化方法
在工作中我们总结出:方案 2 的开销等于方案 1 的第二步的开销,性能提升,由原有的 25 分钟完成,缩短为 10 分钟以内完成。节省了两个临时表的读写是一个关键原因,这种方式也适用于 Oracle 中的数据查找工作。
SQL 具有普适性,很多 SQL 通用的优化方案在 Hadoop 分布式计算方式中也可以达到效果。
5.2无效ID在关联时的数据倾斜问题
问题:日志中常会出现信息丢失,比如每日约为 20 亿的全网日志,其中的 user_id 为主 键,在日志收集过程中会丢失,出现主键为 null 的情况,如果取其中的 user_id 和 bmw_users 关联,就会碰到数据倾斜的问题。原因是 Hive 中,主键为 null 值的项会被当做相同的 Key 而分配进同一个计算 Map。
解决方法 1:user_id 为空的不参与关联,子查询过滤 null
解决方法 2 如下所示:函数过滤 null
调优结果:原先由于数据倾斜导致运行时长超过 1 小时,解决方法 1 运行每日平均时长 25 分钟,解决方法 2 运行的每日平均时长在 20 分钟左右。优化效果很明显。
我们在工作中总结出:解决方法2比解决方法1效果更好,不但IO少了,而且作业数也少了。解决方法1中log读取两次,job 数为2。解决方法2中 job 数是1。这个优化适合无效 id(比如-99、 ‘’,null 等)产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的 数据分到不同的Reduce上,从而解决数据倾斜问题。因为空值不参与关联,即使分到不同 的 Reduce 上,也不会影响最终的结果。附上 Hadoop 通用关联的实现方法是:关联通过二次排序实现的,关联的列为 partion key,关联的列和表的 tag 组成排序的 group key,根据 pariton key分配Reduce。同一Reduce内根据group key排序。
5.3不同数据类型关联产生的倾斜问题
问题:不同数据类型 id 的关联会产生数据倾斜问题。
一张表 s8 的日志,每个商品一条记录,要和商品表关联。但关联却碰到倾斜的问题。 s8 的日志中有 32 为字符串商品 id,也有数值商品 id,日志中类型是 string 的,但商品中的 数值 id 是 bigint 的。猜想问题的原因是把 s8 的商品 id 转成数值 id 做 hash 来分配 Reduce, 所以字符串 id 的 s8 日志,都到一个 Reduce 上了,解决的方法验证了这个猜测。
解决方法:把数据类型转换成字符串类型
调优结果显示:数据表处理由 1 小时 30 分钟经代码调整后可以在 20 分钟内完成。
5.4利用Hive对UNION ALL优化的特性
多表 union all 会优化成一个 job。
问题:比如推广效果表要和商品表关联,效果表中的 auction_id 列既有 32 为字符串商 品 id,也有数字 id,和商品表关联得到商品的信息。
解决方法:Hive SQL 性能会比较好
比分别过滤数字 id,字符串 id 然后分别和商品表关联性能要好。
这样写的好处:1 个 MapReduce 作业,商品表只读一次,推广效果表只读取一次。把 这个 SQL 换成 Map/Reduce 代码的话,Map 的时候,把 a 表的记录打上标签 a,商品表记录 每读取一条,打上标签 b,变成两个<key,value>对,<(b,数字 id),value>,<(b,字符串 id),value>。
所以商品表的 HDFS 读取只会是一次。
5.5解决Hive对UNION ALL优化的短板
Hive 对 union all 的优化的特性:对 union all 优化只局限于非嵌套查询。
消灭子查询内的 group by
示例 1:子查询内有 group by
从业务逻辑上说,子查询内的 GROUP BY 怎么都看显得多余(功能上的多余,除非有 COUNT(DISTINCT)),如果不是因为 Hive Bug 或者性能上的考量(曾经出现如果不执行子查询 GROUP BY,数据得不到正确的结果的 Hive Bug)。所以这个 Hive 按经验转换成如下所示:
调优结果:经过测试,并未出现 union all 的 Hive Bug,数据是一致的。MapReduce 的 作业数由 3 减少到 1。
t1 相当于一个目录,t2 相当于一个目录,对 Map/Reduce 程序来说,t1,t2 可以作为 Map/Reduce 作业的 mutli inputs。这可以通过一个 Map/Reduce 来解决这个问题。Hadoop 的 计算框架,不怕数据多,就怕作业数多。
但如果换成是其他计算平台如 Oracle,那就不一定了,因为把大的输入拆成两个输入, 分别排序汇总后 merge(假如两个子排序是并行的话),是有可能性能更优的(比如希尔排 序比冒泡排序的性能更优)。
消灭子查询内的 COUNT(DISTINCT),MAX,MIN。
由于子查询里头有 COUNT(DISTINCT)操作,直接去 GROUP BY 将达不到业务目标。这时采用 临时表消灭 COUNT(DISTINCT)作业不但能解决倾斜问题,还能有效减少 jobs。
job 数是 2,减少一半,而且两次 Map/Reduce 比 COUNT(DISTINCT)效率更高。
调优结果:千万级别的类目表,member 表,与 10 亿级得商品表关联。原先 1963s 的任务经过调整,1152s 即完成。
消灭子查询内的 JOIN
上面代码运行会有 5 个 jobs。加入先 JOIN 生存临时表的话 t5,然后 UNION ALL,会变成 2 个 jobs。
调优结果显示:针对千万级别的广告位表,由原先 5 个 Job 共 15 分钟,分解为 2 个 job 一个 8-10 分钟,一个3分钟。
5.6GROUP BY替代COUNT(DISTINCT)达到优化效果
计算 uv 的时候,经常会用到 COUNT(DISTINCT),但在数据比较倾斜的时候 COUNT(DISTINCT) 会比较慢。这时可以尝试用 GROUP BY 改写代码计算 uv。
原有代码
关于COUNT(DISTINCT)的数据倾斜问题不能一概而论,要依情况而定,下面是我测试的一组数据:
测试数据:169857条
#统计每日IP
耗时:24.805 seconds
#统计每日IP(改造)
耗时:46.833 seconds
测试结果表名:明显改造后的语句比之前耗时,这是因为改造后的语句有2个SELECT,多了一个job,这样在数据量小的时候,数据不会存在倾斜问题。
6.优化总结
优化时,把hive sql当做mapreduce程序来读,会有意想不到的惊喜。理解hadoop的核心能力,是hive优化的根本。这是这一年来,项目组所有成员宝贵的经验总结。
长期观察hadoop处理数据的过程,有几个显著的特征:
不怕数据多,就怕数据倾斜。
对jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果 多次关联多次汇总,产生十几个jobs,没半小时是跑不完的。map reduce作业初始化的时间是比较长的。
对sum,count来说,不存在数据倾斜问题。
对count(distinct),效率较低,数据量一多,准出问题,如果是多count(distinct )效率更低。
优化可以从几个方面着手:
好的模型设计事半功倍。
解决数据倾斜问题。
减少job数。
设置合理的map reduce的task数,能有效提升性能。(比如,10w+级别的计算,用160个reduce,那是相当的浪费,1个足够)。
自己动手写sql解决数据倾斜问题是个不错的选择。set
hive.groupby.skewindata=true;这是通用的算法优化,但算法优化总是漠视业务,习惯性提供通用的解决方法。
Etl开发人员更了解业务,更了解数据,所以通过业务逻辑解决倾斜的方法往往更精确,更有效。
对count(distinct)采取漠视的方法,尤其数据大的时候很容易产生倾斜问题,不抱侥幸心理。自己动手,丰衣足食。
对小文件进行合并,是行至有效的提高调度效率的方法,假如我们的作业设置合理的文件数,对云梯的整体调度效率也会产生积极的影响。
优化时把握整体,单个作业最优不如整体最优。
7.优化的常用手段
主要由三个属性来决定:
7.1参数设置的影响
如果reduce太少:如果数据量很大,会导致这个reduce异常的慢,从而导致这个任务不能结束,也有可能会OOM 2、如果reduce太多: 产生的小文件太多,合并起来代价太高,namenode的内存占用也会增大。如果我们不指定mapred.reduce.tasks, hive会自动计算需要多少个reducer。

